Blank Language Models
- 9 minsAuthors : Tianxiao Shen, Victor Quach, Regina Barzilay, Tommi Jaakkola MIT Computer Science & Artificial Intelligence Laboratory (MIT CSAIL)
Paper : https://arxiv.org/pdf/2002.03079.pdf
Code : TBA
Summary
Dynamically creating and filling in blanks task에 적합한 Blank Language Model 소개
Language model 에서는 약하지만, 부분을 채우는 task에는 좋은 성능을 보임
Abstract
We propose Blank Language Model (BLM), a model that generates sequences by dynamically creating and filling in blanks. Unlike previous masked language models (Devlin et al., 2018) or the Insertion Transformer (Stern et al., 2019), BLM uses blanks to control which part of the sequence to expand. This fine-grained control of generation is ideal for a variety of text editing and rewriting tasks. The model can start from a single blank or partially completed text with blanks at specified locations. It iteratively determines which word to place in a blank and whether to insert new blanks, and stops generating when no blanks are left to fill. BLM can be efficiently trained using a lower bound of the marginal data likelihood, and achieves perplexity comparable to traditional left-to-right language models on the Penn Treebank and WikiText datasets. On the task of filling missing text snippets, BLM significantly outperforms all other baselines in terms of both accuracy and fluency. Experiments on style transfer and damaged ancient text restoration demonstrate the potential of this framework for a wide range of applications.
1. Introduction
- Left-to-right (autoregressive) 모델들은 text completion 이나 editing task에 적합하지 않음.
- 이러한 task는 text의 부분을 주고 새로운 텍스트를 채워 완성 시키도록 하는 것.
- Masked Language Model (MLM) 이나 Insertion Transformer (Stern et al, 2019)* 는 이러한 task가 가능하지만 잘 맞는 task는 아님.
- MLM은 채워질 텍스트의 길이를 알고 있어야 하고, Insertion Transformer는 어느 곳에 채워져야 할지 명시적으로 컨트롤 할 수 없기 때문.
- 본 페이퍼에서는 Blank Language Model (BLM)을 소개함.
- BLM은 Special symbol 인 “__“을 사용하여 채워야 할 곳을 명시함.
- Special symbol 은 단어로 교체되어 질 수 있을 뿐더러, 새로운 blank (“__“)를 왼쪽, 오른쪽 또는 왼쪽과 오른쪽 둘 다 생성할 수 있음.
- 이러한 과정을 통해 Figure 1. 처럼 하나의 blank (“__”) 에서 여러 단어 (ice cream) 를 채울 수 있음.

- BLM은 하나의 blank나, 텍스트의 부분 (blank를 가진) 채로 시작하며, generation steps을 통해 blanks를 채우고, blank가 남아 있지 않을 때 까지 반복한다.
- BLM을 통해 완성되는 text는 같은 text라도 완성되기까지 trajectory가 여러가지 일 수 있기에 marginal likelihood를 maximizing하는 형태로 학습됨*.
2. Related Work
- Left-to-right generation은 syntax-based 접근법과 methods for learning adaptive generation order를 포함하여 최적의 생성 순서를 찾는데 중점을 둠.
- 이러한 접근법은 특정 순서 (left-to-right)에 맞춰 생성하는 것에 적합함.
- 제안 모델은 누락된 부분을 유연하게 채우는 text rewriting에 적합함.
- 제안 방법과 가장 비슷한 방법은 Insertion Transformer이 존재하지만 이것은 어느 부분이 확장될 것인지 명시적이지 않음.
- MLM 도 마찬가지로 이러한 task를 할 수 있지만, Insertion length를 미리 지정 해야하고 mask token으로 부터 생성될 순서를 결정해야 한다 (dependant 하게 하기 위해서).
3. Blank Language Models
A blank language model (BLM) generates sequences by creating and filling in blanks. Generation starts with a single blank and ends when there is no blank. In each step, the model selects a blank “__”, predicts a word w, and fills the blank with “w”, “_w”, “w_”, or “_w_”. In this way, a blank can be expanded to any number of words.
- Insertion Transformer는 존재하는 토큰들 사이에 아무 곳이나 단어를 insert 할 수 있지만, BLM은 specified blanks에만 insert 할 수 있음.

- Canvas (c = (\(c_1\), … ,\(c_n\))) : Sequence of words interspersed with special “__” tokens.
- b = (\(b_1\), …, \(b_k\)) : Blank location
- w : Word in the vocabulary V
- l, r (0 or 1): Denote whether or not to create a blank to the left and right of w
- theta : The model parameters
- action : Defined as the tuple (b, w, l, r) uniquely specifies the next state of canvas (see Figure 2.)

각 Blank는 nonterminal symbol 이면서도, start symbol이며, terminal symbols은 vocabulary V 로 부터 나온다 (Blank가 없을 때).
생성 규칙은 다음과 같이 제한 됨.
“__” → “__?w__?”, for w in V.
? 은 옵션임을 나타냄. 즉, “w”, “__w”, “w__”, or “__w__”. 4가지 중 1개.
3.1 Model Architecture
- canvas의 (\(c_1\), … \(c_n\)) 을 sequence of representations (\(z_1\), … , \(z_n\)) 을 transformer encoder를 통해 구하고, Blank가 있는 곳은 z = {\(z_{b_1}\), …, \(z_{b_k}\)} 를 얻음.
-
3가지 파트로 joint distribution을 factorize함. (see Fig.3 for an overview)
-
Choose a blank
\[p(b_i|c;\theta) = \text{Softmax}(zu)\]u 는 z를 1차원 logits으로 projection하는 d dimension을 갖는 파라미터.
Note: d는 z의 dim을 나타냄.
-
Predict a word for the selected blank
\[p(w|c,b_i;\theta) = \text{Softmax}(Wz_{b_i})\]W 는 z_b_i를 vocabulary로 projection하는 * V * x d dimension의 파라미터. -
Decide whether or not to create blanks to the left and right of the predicted word
\[p(l,r|c,b_i,w;\theta)=\text{MLP}(z_{b_i},v_w)\]v_w는 w의 word vector, MLP는 (Left / Right) x (Yes / No) 4개의 클래스를 갖는 multilayer perceptron.
-
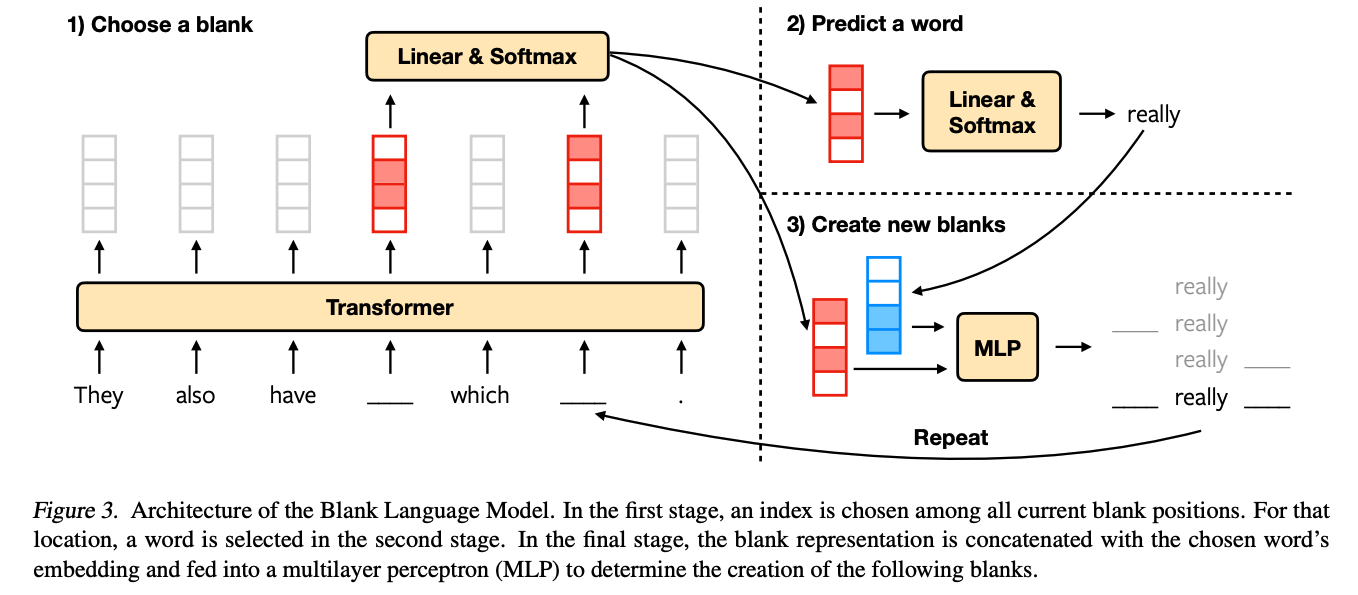
3.2 Likelihood
The same final text “x” may be realized by multiple trajectories. However, if we specify the order in which the words in “x” are generated, the trajectory is also uniquely determined. This follows from the fact that BLM never results in a canvas with two (or more) consecutive blanks.
Trajectories 와 generation orders 사이의 일치는 다음과 같이 marginal likelihood를 정의할 수 있다.
\[p(x;\theta)=\sum\limits_{\sigma\in{S_n}}p(x,\sigma;\theta)=\sum\limits_{\sigma\in{S_n}}\prod\limits_{t=0}^{n-1}p(a_t^{x,\sigma}|c_t^{x,\sigma};\theta)\]
3.3 Training
? : Here we propose training objectives derived from log likelihood. Directly computing the marginal likelihood over n! orders is intractable. We use Jensen’s inequality to lower bound the log likelihood:
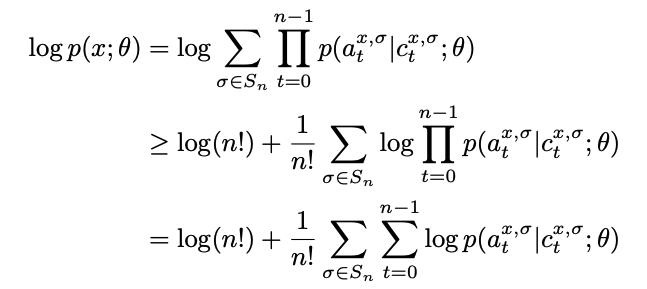
| where equality holds when the posterior p(σ | x; θ) is uniform. |
To train more efficiently, we note that the canvas \(c_t^{x,\sigma}\) depends only on the first t elements of σ. Hence we can combine loss calculations of trajectories that are the same in the first t steps but different at the t + 1 step. Switching the summation order of σ and t, we have:

4. Experiments

- Traditional left-to-right language model 들과 비교
- Text editing task 인 text infilling, ancient text restoration, style transfer 를 진행
- Figure 4. 에서 각 task의 output 확인 가능
Experimental Details
- BLM은 Transformer encoder (base)를 이용하여 sequence of vector representation을 얻음.
- (6 layers, 8 heads, d_model = 512, d_ff = 2048, d_k = d_v = 64)
- MLP 에서 사용되는 hidden layer size는 1024
- Weight decay, learning rate, dropout rate, beam size는 validation set을 통해 조절
We note that beam search in BLM does not search for the sentence with the maximum marginal likelihood p(x; θ), but instead for a sentence and a trajectory that have the maximum joint likelihood p(x, σ; θ).
4.1. Language Modeling
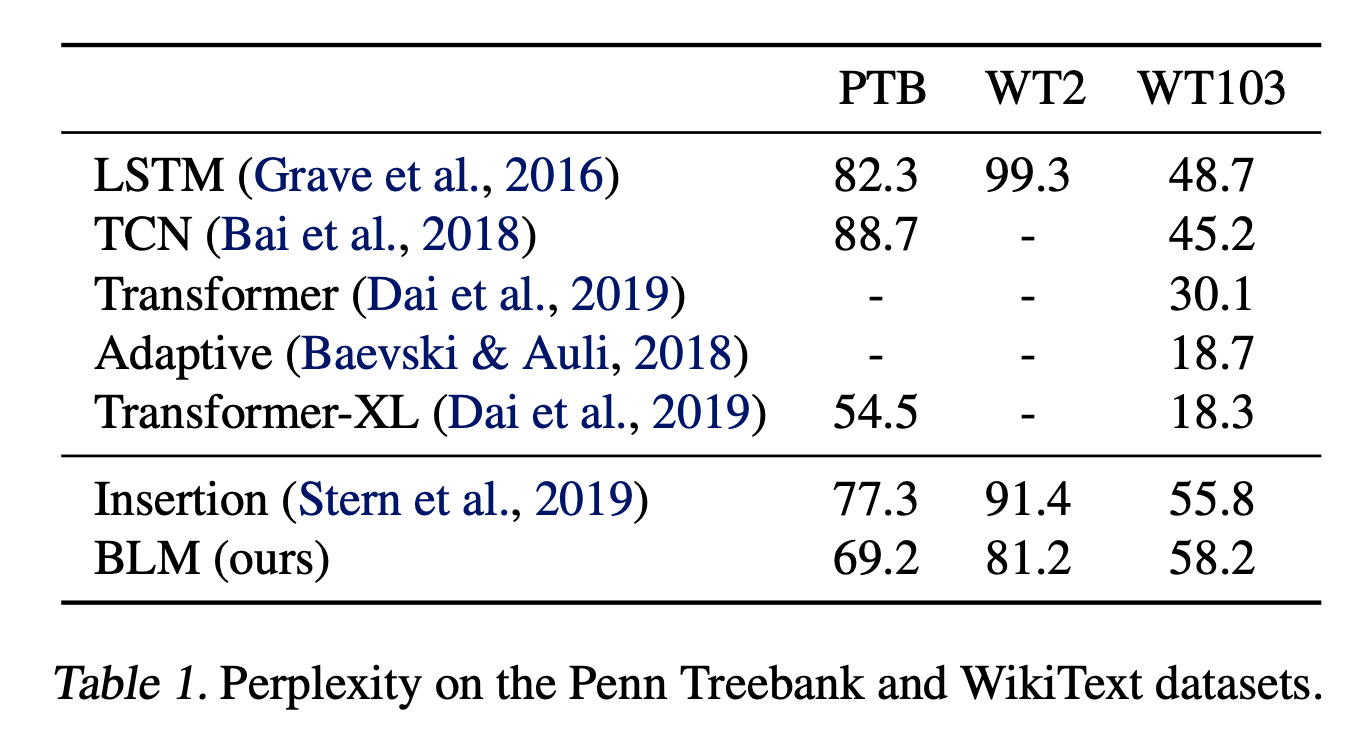
- Dataset : Penn Tree Bank (PTB), WikiText-2 (WT2) and WikiText-103 (WT103)
- Result : Table 1 summarizes the perplexity of our model in comparison with previous work.
- Adaptive embedding method와 Transformer-XL이 좋은 결과를 얻었지만, 해당 기법들은 BLM과 달리 추가적인 이점이 있거나 기타 테크닉이 많이 사용 되고 모델 사이즈도 큼. (250M / BLM : 42M)
- 이런 점은 BLM에도 적용이 가능하고 이런 것에 빗대어 봤을때, Insertion Transformer, LSTM, TCN이 비교 대상에 적합함
- 또한, 이러한 Language modeling task는 BLM과 같은 free-order model 에서는 취약함.
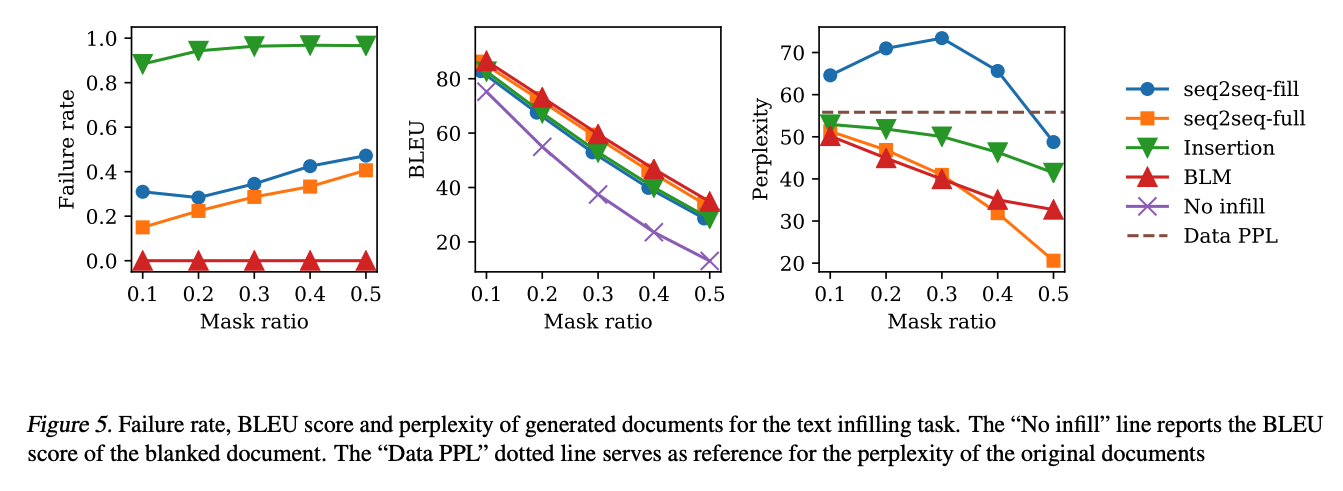
4.2. Text Infilling
Text infilling task는 텍스트의 일부분을 가지고 나머지 부분을 채우는 task (Figure 4. 에서 확인 가능)
Context와 semantic consistency를 유지하면서 공백을 채우는 능력을 평가함.
- Dataset : Yahoo Answers dataset Document x 에 r % 의 토큰에 randomly mask 적용 후 인접한 mask tokens 은 하나의 blank token으로 변환하여 사용.
- Baselines
- seq2seq-full : c 가 주어졌을 때, full document x 를 생성하는 transformer model. c에 있는 기존 토큰이 없거나 형식이 맞지 않을 수 있음.
- seq2seq-fill : full과 같지만, blank만 채우고, 기존 c에 있는 토큰을 생성하지는 않음. 다만, 여전히 c에서 주어진 blank 보다 많거나 적게 생성 할 수 있음.
- Insertion Transformer : 생성되는 위치를 명시적으로 컨트롤할 수 없음. 따라서 모든 blank를 못 채울 수 있음.
- Metrics : BLEU score, Failure rate
- Results : See Figure 5 and 6. seq2seq 모델은 language model에 강력하지만, 중간에 채우는 작업에는 부족함.

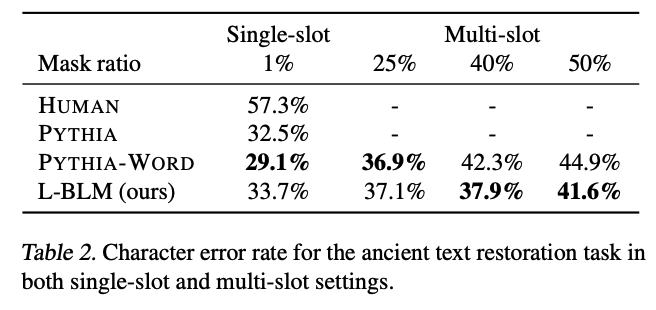
4.3. Ancient Text Restoration
Ancient text restoration은 ancient documents의 일부를 복원하는 text infilling task.
Character-level 이기 때문에, “?” symbol로 character 수를 알려 줌.
이러한 task를 위해 Length-aware BLM 사용.
- Length-aware Blank Language Model (L-BLM)
- Blank “__” 대신 special token “__[t]__” token을 사용
- t 는 “?”의 수를 나타냄. 즉, 복원해야 할 character의 수
- ex) “???” → “__[3]__”
- Dataset : PHI-ML dataset
- single-slot과 multi-slot 으로 평가
- Baselines
- PYTHIA : Seq2seq based approach specialized in ancient text restoration.
- PYTHIA-WORD : A variant of PYTHIA, uses both character and word representation as input.
- Metrics : Character error rate (CER)
- Results : See Table 2.
- Real world 에서는 multi-slot이 많음
4.4. Sentiment Transfer
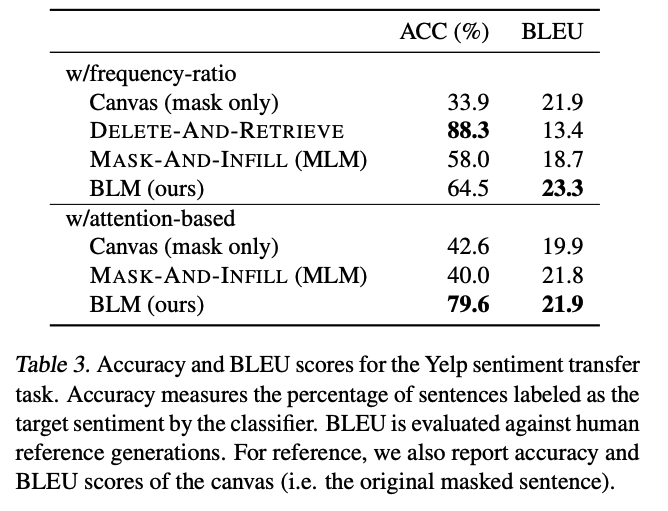
Sentiment transfer task는 topic을 유지하면서 문장의 sentiment를 바꾸는 것.
Style transfer의 two-step approach 채택
- Remove words and expressions of high polarity from the source sentence;
- Complete the partial sentence with words and expressions of the target sentiment.
Step 1 에서는 frequency-ratio, attention scores 베이스 방법 2가지가 존재함.
Step 2 에서는 model을 통해서 시행
sentiment가 2개일 때는 각 sentiment 마다 BLM을 학습 시킴
- Dataset : Yelp review dataset
- Baselines
- Delete-and-retrieve method : Seq2seq-based approach where hidden representations of the masked sentence is concatenated with a learned attribute embedding before decoding.
- Mask-and-infill model : Based on a pretrained BERTbase model and then finetuned by conditioning on the sentiment of the sentence to reconstruct.
- Metrics : Pretrained CNN classifier accuracy and BLEU
- Results : See Table 3. and Figure 7.
5. Conclusion
In this paper, we proposed the blank language model for flexible text generation. BLMs can generate sequences in different orders by dynamically creating and filling in blanks. We demonstrate the effectiveness of our method on various text rewriting tasks, including text infilling, ancient text restoration and style transfer. Future work may explore sequence modeling tasks beyond text rewriting that also benefit from flexible generation order. An example is music modeling: harmonic constraints naturally impose a canvas that composers fill in with the melody.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA