Self-training Improves Pre-training for Natural Language Understanding
- 11 minsAuthors : Jingfei Du, Edouard Grave, Beliz Gunel, Vishrav Chaudhary, Onur Celebi, Michael Auli, Ves Stoyanov, Alexis Conneau / Facebook AI, Stanford University
Arxiv
Paper : https://arxiv.org/pdf/2010.02194.pdf
Code : https://github.com/facebookresearch/SentAugment
Summary
- External unlabeld data를 사용하는 SentAugment 제안
- SentAugment, a data augmentation method which computes task-specific query embed- dings from labeled data to retrieve sentences from a bank of billions of unlabeled sentences crawled from the web.
- Retrieval task에서는 Transformer encoder를 triplet loss로 훈련 시킨 것을 사용한다.
- Unannotated data에서 먼저 사용할 데이터를 선별 한 후, 모델을 이용해서 레이블링을 해줌
- Augmentation data는 기존 training set의 비율(분포)를 따르도록 조절함
- Student 모델은 기존 학습 데이터를 사용하지는 않고 새로 생성된 데이터를 바탕으로 Teacher model로 부터 얻은 soft label로 학습함
- Sentence embedding 은 여기서 제안하는 SASE 사용
- Domain adaption에서는 continued pretraining 보다 self-training이 더 좋음
- 많은양의 aug data를 sent augment에서 택하면 성능이 오름
- Retrieval selection 마다 성능 증가가 다르지만 label-avg가 가장큼
- KLD로 학습할 때 label을 discrete보다는 logits (continuos) 하게 주는 것이 더 좋음
개인적 견해
- 외부 데이터를 이용한 방법은 좋은 방법이라고 생각됨
- 외부 데이터를 어떤 방식으로 정제할 것인지 또는 레이블링 할지가 중요할 것으로 보이며 이에 들어가는 시간 및 자원도 중요함
- Augmenated data를 많이 사용하면 성능 향상을 보인다는 중요한 결과를 보임
- Hard labeling 방법보단 soft가 역시 좋을것 같았음
- 개인적으로 재미있게 본 논문
- 필드에서 사용 될 가능성이 높아보임
Abstract
Unsupervised pre-training has led to much recent progress in natural language understanding. In this paper, we study self-training as another way to leverage unlabeled data through semi-supervised learning. To obtain additional data for a specific task, we introduce SentAugment, a data augmentation method which computes task-specific query embeddings from labeled data to retrieve sentences from a bank of billions of unlabeled sentences crawled from the web. Unlike previous semisupervised methods, our approach does not require in-domain unlabeled data and is therefore more generally applicable. Experiments show that self-training is complementary to strong RoBERTa baselines on a variety of tasks. Our augmentation approach leads to scalable and effective self-training with improvements of up to 2.6% on standard text classification benchmarks. Finally, we also show strong gains on knowledge-distillation and few-shot learning.
1. Introduction
- Self-training은 unlabeled data에 대해 synthetic label을 생성하기 위해 labeled data와 teacher model을 이용하는 방법이다.
- 이러한 synthetic label은 student model에서 사용된다.
- 이러한 방법은 student model이 teacher model과 비슷하거나 더 높은 capacity를 가질 때 self-training이라고 하고, 작을 때는 Knowledge Distillation (KD) 라고 한다.
- Pre-training (semi-supervised method) 과 self-training은 같은 정보를 얻는지 아니면 상호 보완적인지에 대한 물음을 던질 수 있다.
- 최근 연구에서는 pre-training 이외에도 self-training이 성능 향상에 도움을 준다는 것을 보인다.
- 하지만 NLP와 달리 ImageNet을 Pre-trained model로 사용할 경우 downstram task에 많은 데이터가 존재한다면, pre-training이 도움이 되지 않는다.
- (Rethinking Pre-training and Self-training, 2020)
- 풀고자 하는 문제를 위한 많은 labeled data가 있고, 강한 data augmentation을 이용하면 pre-training의 성능이 떨어진다.
- Pre-training과 달리 Self-training은 강한 data augmentation을 사용하는게 유용하다.
- Pre-training이 성능을 향상시키는 경우라면, Self-training은 그 이상의 성능향상을 가져온다.
- REFERENCE
- 두 방법은 모두 downstream domain과 동일한 도메인에서 unlabeled data가 있다고 가정을 한다.
- 이러한 assumption은 low-resource downstram task의 경우 제한적이다.
- 따라서 두번째 물음을 던질 수 있는건, ‘특정 도메인에서 unlabeled data를 어떻게 대량으로 얻을 수 있는가’ 이다.
- 본 논문에서는 Web상에서 크롤링하여 얻은 데이터로 부터 “in-domain” 데이터를 만드는 SentAugment를 제안한다.
- Sentence embedding을 구축하며, 그것을 통해 retrieval 방법론으로 unannotated sentences에 대해 label을 부여한다.
- Sentence embedding model은 triplet loss를 통해 similarity search에 최적화 되어 있다.
- Labeled data에 대해 teacher model을 학습하고, 이를 통해 retrieved sentence에 label을 부여한다.
- 그 후 synthetic dataset을 통해 student model을 학습한다.
- 실험 결과 SentAugment는 self-training, KD, few-shot learning 에 효과적임.
- Self-training이 PLM의 strong baseline을 보완해준다는 첫번째 연구라고 함
- Contribution
- We introduce SentAugment, a data augmentation approach for semi-supervised learning that retrieves task-specific in-domain data from a large bank of web sentences.
- We show that self-training improves upon unsupervised pretraining: we improve RoBERTa-Large by 1.2% accuracy on average on six standard classification benchmarks.
- We show that self-training improves accuracy by 3.5% on average for few-shot learning.
- For knowledge-distillation, our approach improvesthe distilled RoBERTa-Large by 2.9% accuracy on average, reducing the gap between the teacher and the student model.
- We will release code and models for researchers to build on top of our work.
2. Approach
SentAugment 방법은 self-training을 위해 large bank of sentences에서 task-specific in-domain unlabeled data를 얻어 teacher model을 통해 label을 부여한다. 이때 teacher model로는 RoBERTa-Large가 사용된다.
이렇게 얻어진 데이터들은 student model을 학습하는데 사용된다.
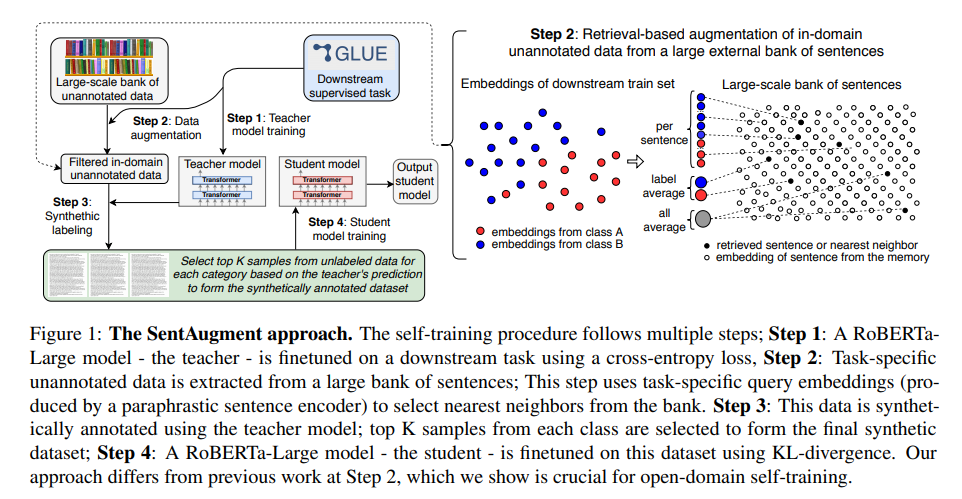
2. 1. SentAugment: data augmentation for semi-supervised learning
대부분의 semi-supervised approaches는 in-domain labeled data에 의존하지만, 우리는 external data로 부터 이러한 데이터를 구축한다.
- Large-scale sentence bank
- 크롤링된 데이터에서 downstream task와 관련된 데이터를 가져온다.
- 이때 universal paraphrastic sentence encoder 를 사용한다.
- 이러한 Sentence encoder 는 word2vec embeddings와 uSIF를 비교 대상으로 고려한다.
- 또한, 저자들의 sentence embedding model은 MLM으로 pre-trained 된 모델에 유사 문장간의 cos similarity를 최대화 하도록 triplet loss를 통해 학습시킨다.
- Downstream task embeddings
- all-average : downstream task에 사용되는 training set의 sentence embedding을 average한 것
- label-average: label 별로 하나의 embedding을 average를 통해 만드는 것
- per-sentence: 각 문장 하나하나에 대해 embedding을 그대로 사용하는 것
- Unsupervised data retrieval
- Large sentence bank에 대해 위에서 구한 embedding을 바탕으로 retrieval 해서 in-domain candidates data를 얻음
- Downstream task dataset의 label 비율을 유지하면서 teacher model을 통해 얻을 수 있는 high-confident sample 만을 필터링 하여 사용함.
- 상대적으로 작은 task의 경우 100배 정도를 사용하며, 중간정도 사이즈의 task는 10배 정도 사용한다.
2. 2. Semi-supervised learning for natural language understanding
Data augmentation technique을 self-training과 KD를 결합하여 사용하여 이득을 얻는다.
-
Self-training
Figure 1. 참고
- RoBERTa-Large를 target downstream task에 대해 fine-tuning
- 해당 모델을 retrieved in-domain sentences에 대해 labeling 하는 데 사용 (soft-labeling)
- Confidence score 기준으로 높은 것만을 사용
- 기존 dataset의 label 비율과 동일하게 맞춤
- Student model로, RoBERTa-Large를 위에서 얻어진 데이터를 바탕으로 KL-divergence로 학습시킴
- Knowledge-distillation
- We follow the same approach for knowledge-distillation, except we consider a student model that has an order of magnitude less parameters than the RoBERTa-Large teacher model.
- As for self-training, we pretrain the student and use continuous probabilities as synthetic labels. We exploit data augmentation by using in-domain unannotated sentences.
- Few-shot learning
- 클래스 당 몇개의 샘플만 고려하여 several downstream tasks에 대해 시뮬레이션 함
- 데이터를 2~3배 augmentation 하여 테스트함
3. Experimental setup
3. 1. Large-scale bank of sentences
- Common-Crawl 이용
- Sentence segementer 이용하여 문서를 문장단위로 쪼개고 중복 제거
- 3개의 corpora 이용
- CC-100M : 100M 문장 (2B 단어)
- CC-1B : 1B 문장 (20B 단어)
- CC-5B : 5B 문장 (100B 단어)
- Retreival 할 때 테스트셋과 동일한 문장 제거
3. 2. Evaluation datasets
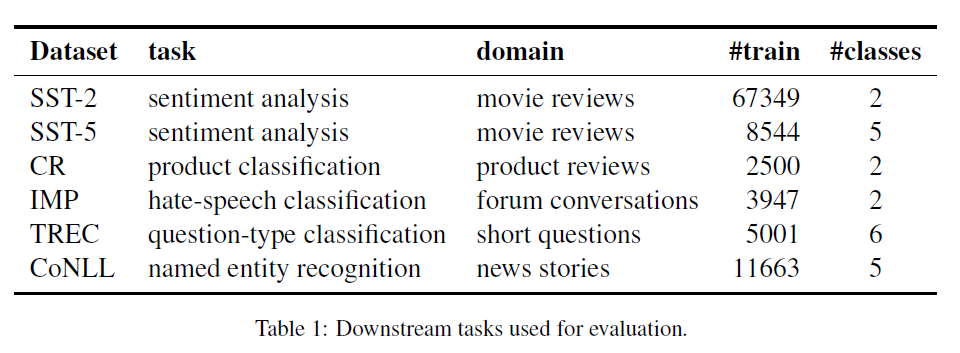
- SST-2
- SST-5
- Product classification (CR)
- Hate-speech comment classification (IMP)
- Question classification (TREC)
- NER (CoNLL 2002)
3. 3. Training details
- Our sentence embeddings
- SentAugment Sentence Encoder (SASE) 사용
- NLI entailment pairs, MRPC, Quora Question Pairs (QQP), round-trip translation web paraphrases, OpenSubtitles and Europarl 사용
- 즉, Paraphrase dataset이나 parallel dataset을 이용하여 sentence encoder를 학습함
- Multilingual masked language model을 pretraing 해서 사용 (영어, 프랑스어, 이탈리아어, 인도네시아어)
- Triplet loss를 이용하여 학습
- 이렇게 학습 된 모델은 Semantic Textual Similarity (STS) 벤치마크에 대해 평가함
- Pretraining과 긴 문장에 대한 학습이 CommonCrawl의 문장에 대해 적합하다는 것을 발견
- Word2Vec 및 uSIF와 비교함
- Fine-tuning the student model
- fairseq 사용
- Baseline과 downstream task의 finetuning 용도로 RoBERTa-Large를 사용
- Adam
- lr : 1e-5
- batch size : 16
- dropout rate : 0.1
-
Fine-tuning 시 KL divergence 사용
We found that fine-tuning again on the training set of the downstream task with ground-truth labels was not necessary, neither was adding ground-truth sentences from the training set to the self-training data.
- Few-shot learning experiments
- 각 레이블 별로 20개의 데이터를 가지는 5개의 training set을 구성
- label distribution을 고려하여 validation set에서 200개의 example을 샘플링하여 validation set 구성
- test set은 그대로 사용
- 10개 seed로 실험하였고, 상위 3개모델의 평균 테스트 정확도를 측정
- 이를 기반으로 5개의 training set으로 학습하여 테스트함
- 이 실험에서는 full-shot setting과는 달리 discrete label 사용, 학습 셋에 ground truth data를 사용, augmentation data 상위 1000개에서 기존의 데이터 크기 (레이블 별 20개) 만큼 샘플링해서 증가시킴
- Teacher model이 성능이 좋지 않을 것이므로 student model에 사용되는 전체 데이터 셋이 noisy 한 데이터가 full-shot setting에 비해 더 많아 질 수 있으므로 해당 방식 채택
4. Analysis and Results
4. 1. Self-training experiments
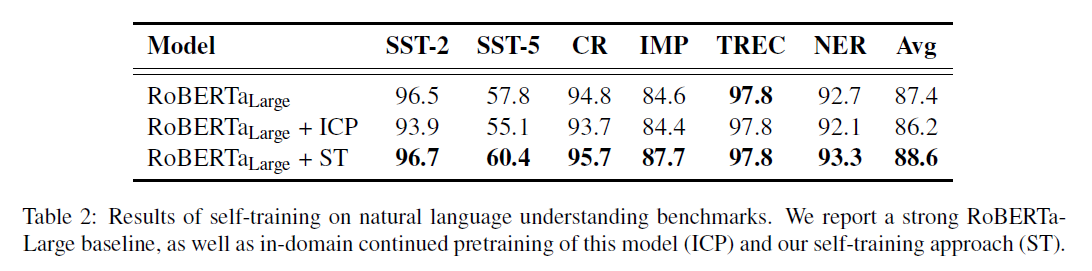
- In-domain continued pretraining은 RoBERTa-Large 에 대해 retrieved in-domain augmented data를 가지고 pretraining을 더 진행 한 것
- ST가 ICP와 같은 domain adaption만을 하는지 확인 하기 위함
- ST 만으로도 성능 향상을 보임
- ICP의 경우 오히려 감소하는 것을 보임
- 즉 성능향상이 In-domain data를 사용뿐만 아니라 self-training algorithm과의 조합에 영향이 있음을 보임
- ST는 fine-tuning step에서 generalization을 개선하고 domain adaption을 하는 방법임
4. 2. Few-shot learning experiments
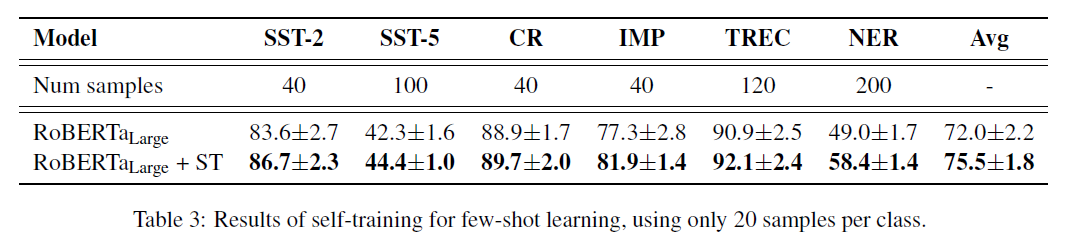
- Few-shot learning에서도 성능이 향상됨
4. 3. Knowledge distillation experiments
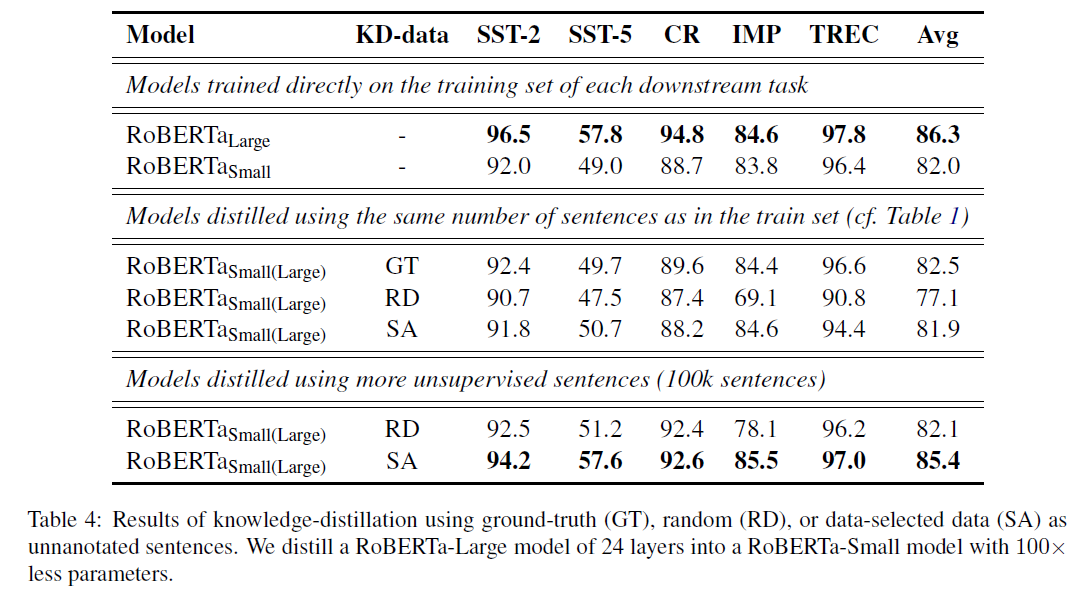
- KD에서도 Large-scale augmentation의 이점을 얻을 수 있음
- Random sentence를 사용하는 것 보다 ground-truth를 사용하는 것이 성능이 더 좋음
- In-domain data가 중요하다는 가정하는 것이 중요하다는것을 보여줌
- SA를 사용할 경우 격차를 줄일 수 있음
- 더 많은 문장을 사용할 경우 성능 격차를 줄이며, SA를 이용하여 많은 문장을 사용할 경우 성능이 증가함을 보인다.
- 10배 더 작은 모델로 Large 모델을 거의 근접 할 수 있음.
4. 4. Ablation study of data augmentation
- Task-specific retrieval
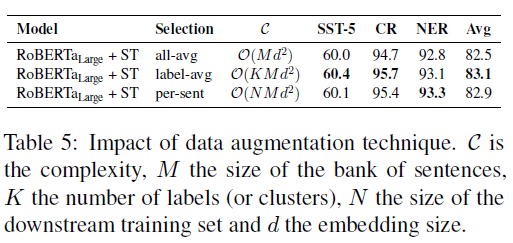
- label-average 를 사용하는 것이 성능이 가장 좋음
- Unbalanced classes가 존재할 경우 많은 데이터를 갖는 label이 더 과도하게 표현될 수 있기 때문이며, label-average가 더 많은 다양성을 제공함
-
Sentence embedding space
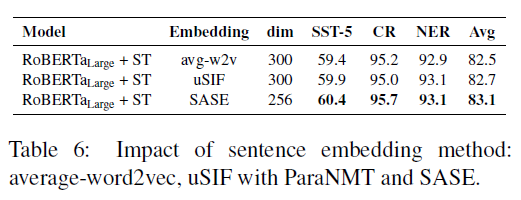
- 문장 임베딩은 외부 텍스트 데이터를 얻는 것에 큰 영향을 미치므로 중요함
- SASE가 가장 좋은 성능을 얻음
-
Scaling bank size
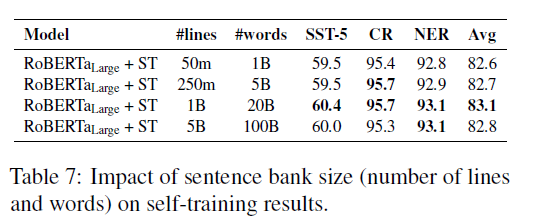
- 1B 까지는 증가하지만 5B로 올려도 큰 증가는 없음
- Corpus 사이즈를 늘리는 것은 retrieved sentences의 다양성을 줄이는 것 일 수 도 있음.
- (비슷한 문장들이 많아져서 ??)
- (비슷한 문장들이 많아져서 ??)
-
Continuous labels
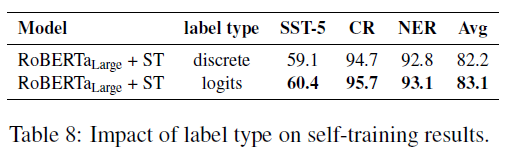
- Soft label을 사용할 시 성능이 더 향상됨
- CV 에서 연구된 결과와는 달리 discrete label 사용시 별로 이득을 얻지 못함 (CR, NER)
- Computational cost of self-training
- SentAugment data prefiltering reduces the amount of data to be annotated by the teacher model and also filters based on the target domain. Filtering based solely on classifier confidence is significantly more expensive computationally, as annotating 10000 sentences with RoBERTa-Large takes approximately 3 seconds on a Volta-32GB GPU. This means that annotating 1B sentences takes 83 hours on a single GPU and much longer for models of larger size such as T5 (Raffel et al., 2019) or GPT-3 (Brown et al., 2020). On the other hand, using SentAugment based on a few task-specific query embedding (label-average) takes one minute for scoring 1B sentences. By only selecting the first few million top sentences, or less, to synthetically annotate, this greatly reduces computational cost and allows to scale to a larger bank of sentences, which in turn allows for more domains to be considered. Note that similarity search can be further sped up significantly by using fast nearest neighbor search such as product quantization with inverted files (Johnson et al., 2019).
5. Analysis of similarity search
5. 1. Sentence embeddings (SASE)
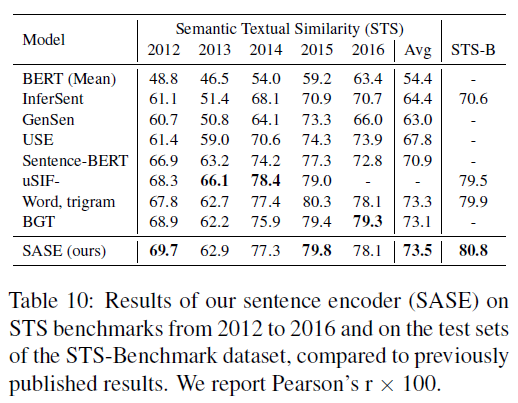
- SASE가 성능이 우수하다
5. 2. Examples of large-scale similarity search

6. Conclusion
Recent work in natural language understanding has focused on unsupervised pretraining. In this paper, we show that self-training is another effective method to leverage unlabeled data. We introduce SentAugment, a new data augmentation method for NLP that retrieves relevant sentences from a large web data corpus. Self-training is complementary to unsupervised pre-training for a range of natural language tasks and their combination leads to further improvements on top of a strong RoBERTa baseline. We also explore knowledge distillation and extend previous work on few-shot learning by showing that open domain data with SentAugment is sufficient for good accuracy.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA