SSMBA: Self-Supervised Manifold Based Data Augmentation for Improving Out-of-Domain Robustness
- 12 minsAuthors : Nathan Ng (University of Toronto Vector Institute), Kyunghyun Cho (New York University), Marzyeh Ghassemi (University of Toronto Vector Institute)
EMNLP2020 Paper : https://www.aclweb.org/anthology/2020.emnlp-main.97.pdf Code : https://github.com/nng555/ssmba
Summary
- Corruption Function과 Reconstruction Function을 정의해서 Denoising Auto-Encoder 방식으로 데이터를 생성
- Corruption function으로는 MLM을 Reconstruction function으로는 RoBERTa 사용
- Self-Supervision을 통해 생성된 데이터에 대해 레이블링
- Out-Of-Domain (OOD) 데이터에 대해서도 성능이 향상됨
- EDA / CBERT / UDA 와 비교
개인적 견해
- CBERT 이후에 나온 GPT2 / BART를 이용한 모델과 비교하지 않은 점이 아쉬움
- CBERT와 거의 비슷하지만 모델이 RoBRETa 로 바뀐 점, 그리고 레이블링을 하지 않는 점, 그리고 fine-tuning을 하지 않는 점이 다름
- CBERT에서는 가정이나 가설같은게 존재하지 않았는데, 이 논문에서는 그럴싸한 가설을 가져오고 가정을 함
- 다양한 분석이 Accept 요인이지 않을까?
- 튜닝 할 것이 많은 것 같다.
- 어~~~디서 많이 본 것과 비슷한데….? (Ma….)
Abstract
Models that perform well on a training domain often fail to generalize to out-of-domain (OOD) examples. Data augmentation is a common method used to prevent overfitting and improve OOD generalization. However, in natural language, it is difficult to generate new examples that stay on the underlying data manifold. We introduce SSMBA, a data augmentation method for generating synthetic training examples by using a pair of corruption and reconstruction functions to move randomly on a data manifold. We investigate the use of SSMBA in the natural language domain, leveraging the manifold assumption to reconstruct corrupted text with masked language models. In experiments on robustness benchmarks across 3 tasks and 9 datasets, SSMBA consistently outperforms existing data augmentation methods and baseline models on both in-domain and OOD data, achieving gains of 0.8% accuracy on OOD Amazon reviews, 1.8% accuracy on OOD MNLI, and 1.4 BLEU on in-domain IWSLT14 German-English.
1. Introduction
- Training distributions (train set)은 test distribution을 전부 커버하지 못하는 경우가 많다.
- 이는 Biased dataset collection 또는 test distribution drift over time 으로 인해 나타난다.
- 따라서 unseen examples에 대해 강건하도록 학습시키는 것이 machine learning model 학습의 키포인트이다.
- 일반적으로 전체 분포로 일반화하는 것은 불가능 하므로 Out-Of-Domain (OOD) robustness 에 목표를 맞춘다.
- Data Augmentation (DA)는 OOD robustness를 향상시키는 일반적인 방법이다.
- 만약 데이터가 low-dimensional manifold에 집중되어 있다면, 그 데이터에 의해 DA된 데이터는 원래 데이터의 주변에 있어야 한다.
- 이러한 perturbation 방법론들 (DA) 는 semi-supervised and self-supervised settings에서 성능 향상 또는 일반화가 되는걸 보여주었다.
- 이미지 데이터는 회전이나 간단한 transformation을 통해 DA가 가능하지만, NLP는 의미를 보존하면서 DA 하기가 힘들다.
- 본 논문에서는 Self-Supervised Manifold Based Data Augmentation (SSMBA)를 제안한다.
- SSMBA는 휴리스틱하게 특성화하기 어려운 도메인에서 DA를 하는 방법이다.
- 휴리스틱한 방법론으로 NLP는 DA하기 어렵다는 뜻
- Denoising auto-encoder을 모티브로함
- Corruption function을 통해 data manifold에서 확률적으로 examples을 off (perurb) 한다.
-
그 다음 Reconstruction function을 통해 back on (project) 한다
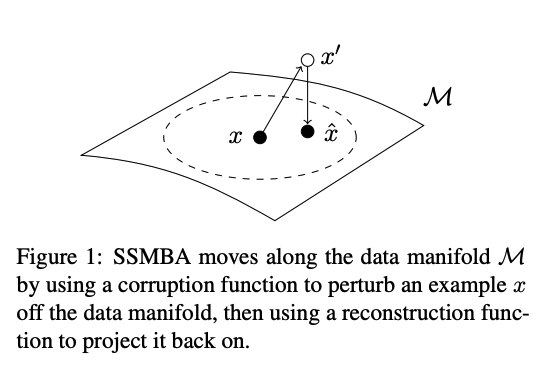
- 이런 방식으로 하면 DA 된 데이터가 원래 데이터의 주변에 놓이게 된다.
- SSMBA는 모든 supervised task에 적용할 수 있으며, task-specific한 knowledge가 필요하지 않고, class- 또는 dataset-specific fine-tuning이 필요하지 않다.
- 감정 분석, 자연어 추론 및 기계 번역에서 SSMBA를 사용하는 방법을 조사함
- 9개의 데이터 세트와 4개의 모델에 대한 실험에서 SSMBA가 In-domain 및 OOD 데이터 모두에서 baseline과 다른 방법론보다 좋음
2. Background and Related Work
2. 1. Data Augmentation in NLP
- 과거 연구들은 일반화를 개선하기 위한 방법으로 DA을 사용하였으며, 기존 데이터를 바탕으로 새로운 데이터를 만드는 방식을 사용했다
- Semi-supervised learning 및 self-supervised learning settings에서 효과적인 이러한 방법들은 local perturbation에 대한 robustness를 유도한다고 가정한다.
- Task-specific한 방법들이 존재하는데, 예를 들면 휴리스틱 기반, back-translation, consistency training, word embedding을 이용하는 방법, Language model을 이용하는 방법이 있다.
- 최근에는 PLM을 이용하여 샘플을 생성하거나, contextual language model을 finetuning하여 사용하는 방법이 있다.
2. 2. VRM and the Manifold Assumption
- Vicinal Risk Minimization (VRM)은 기존 training data 주변에서 샘플을 추출하여 training data를 확대하는 것으로 DA를 정의한다.
- VRM에 대해 알아보자
- 일반적으로 우리에게 주어진 데이터를 가지고 학습하는 방식을 Empirical Risk Minimization (ERM) 이라고 한다.
- 이 Empirical data의 주변부(vicinity) 분포를 모델링하여 이 Vicinal data distribution에 대해 학습하는 것을 VRM이라고 한다.
- 즉 기존 데이터에 local perturbation을 주는 방식을 Vicinity 분포를 모델링하는 방식이라고 볼 수 있다.
- 따라서 DA via local perturbation 를 사용한 학습은 VRM이라고 할 수 있다.
- 일반적으로 training data의 주변은 데이터 세트에 따른 휴리스틱을 사용하여 정의함.
-
Computer Vision 분야에서는 scaling을 하거나 color를 변경하거나 translation, roation을 하는 방식.
- Manifold assumption은 고차원 데이터가 저차원 manifold에 놓여 있다는 것을 말함.
- 이 가정을 통해 trainining example의 주변부를 data manifold에 있는 주변부분인 manifold neighborhood로 정의할 수 있다
- This assumption allows us to define the vicinity of a training example as its manifold neighborhood, the portion of the neighborhood that lies on the data manifold.
- 최근 Manifold assumption을 바탕으로 decision boundary를 확장하거나, adversarial example을 생성하거나, 두개의 example을 interpolation하는 방식 또는 affine transformation을 하여 robustness를 증가시켰다.
2. 3. Sampling from Denoising Autoencoders
- Denoising AutoEncoder (DAE)는 conditional distribution \(P_\theta(x\vert x')\) 을 통해 stochastically corrupted \(x'\sim q(x'\vert x)\) 된 clean input \(x\)를 reconstruction 하도록 학습한다.
- Pseudo-Gibbs Markov chain 을 이용
- Training dataset이 증가하면 실제 데이터 생성 분포 P(x)에 근접하게 된다.
- 이러한 process는 P(x)가 분포되어 있는 매니폴드를 따라 샘플링을 할 수 있도록 함.
2. 4. Masked Language Models
- BERT 및 다른 여러모델에서 쓰인 것 처럼 일정 퍼센트의 토큰을 랜덤하게 corruption (masking)하고 원래 토큰을 reconstruction 하도록 학습하는 것 (MLM task)
- 여기서는 MLM을 이용하여 DAEs를 할것이다.
-
Figure 2
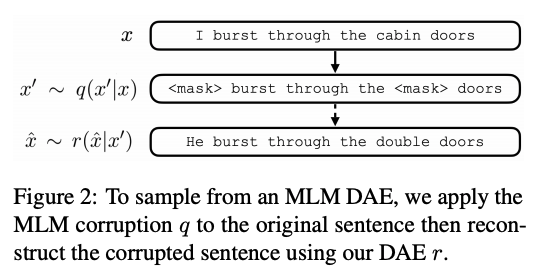
3. SSMBA: Self-Supervised Manifold Based Augmentation
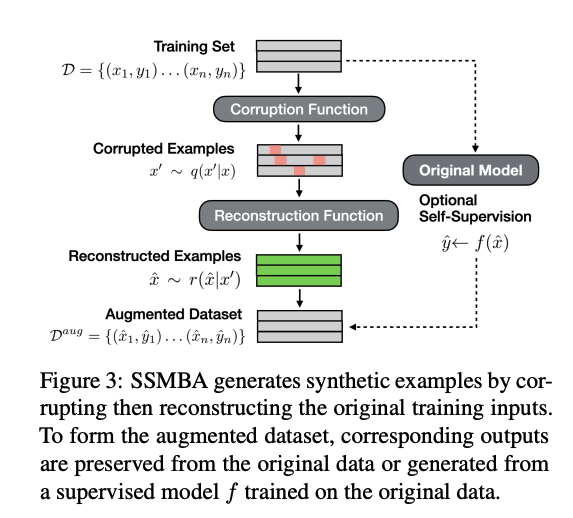
- 먼저, 입력 데이터들이 저 차원 데이터 매니폴드 \(M\)에 놓여있다고 가정함
- \(q\) 는 corruption function, \(x'\sim q(x'\vert x)\) such that \(x'\) no longer lies on \(M\).
- \(r\) 은 reconstruction function, \(\hat{x} \sim r(\hat{x}\vert x')\) such that \(\hat{x}\) lies on \(M\).
- \((x_i, y_i) \in D ,\\ x_i'\sim q(x'\vert x_i), \\ \hat{x}_{ij} \sim r(\hat{x}\vert x_i')\) 방식으로 DA를 한다.
- 각 input data에 의해 생성된 데이터의 label (\(\hat{y}_{ij}\)) 는 기존 input data의 label 인 \(y_i\)를 보존하거나 original data로 훈련된 teacher model을 통해 soft 및 hard 레이블을 사용할 수 있다.
- SSMBA를 NLP에 적용을 할 것이며, \(q\) 로는 MLM을, \(r\) 로는 pre-trained BERT 모델을 사용한다.
- 다른 DA 방식과는 다르게 fine-tuning이 필요하지 않으며, supervised learning에 대부분 적용할 수 있다.
- \(q, r, dataset\) 만이 필요하다.

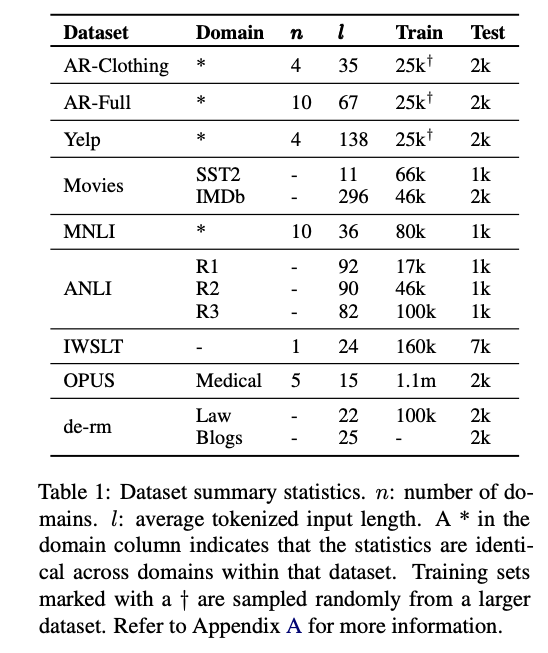
4. Datasets
- 총 9개의 데이터셋을 사용
- 4개의 sentiment analysis datasets
- 2개의 natural language inference (NLI) datasets
- 3개의 machine translation (MT) datasets
-
데이터셋 상세 정보
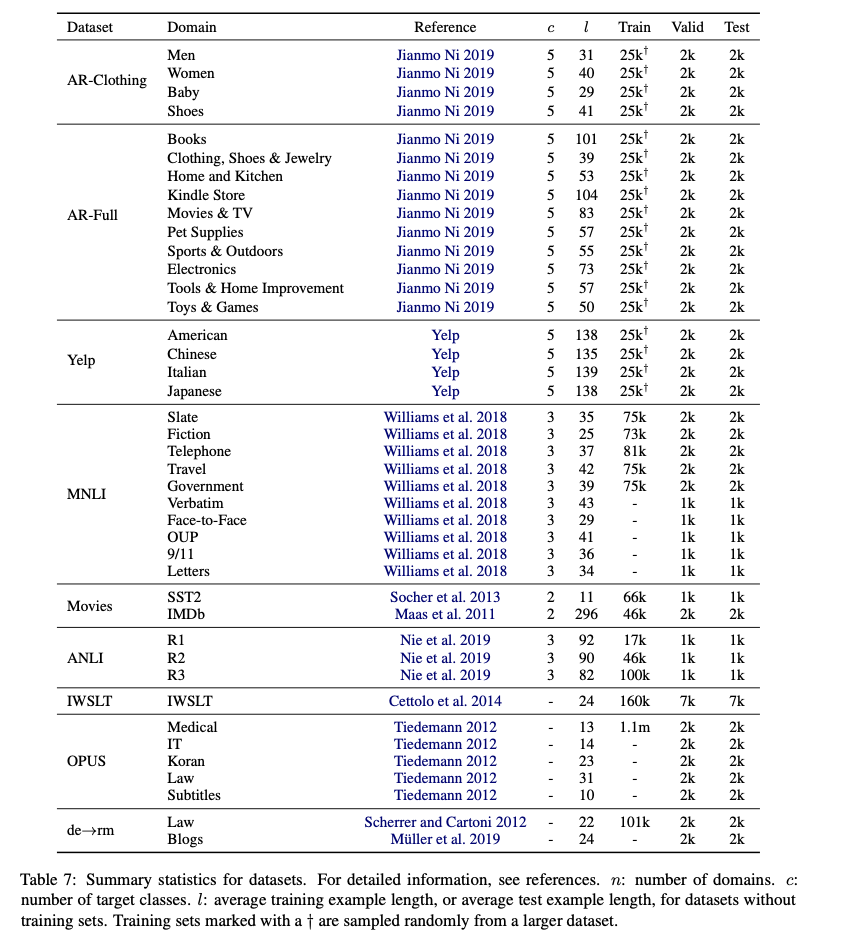
4.1. Sentiment Analysis
- The Amazon Review Dataset (1 to 5 star rating)
- AR-Full : contains reviews from the 10 largest categories
- AR-Clothing : contains reviews in the clothing category seperated into subcategories by metadata
- Movies dataset
- SST2 : contains movie review excerpts
- IMDb dataset : contains full length movie reviews
- Yelp Review Dataset : contains restaurant reviews with associated business metadata (1 to 5 star rating)
4.2. Natural Language Inference
- MNLI : corpus of NLI data from 10 distinct genres of written and spoken English.
- ANML : corpus of NLI data designed adversarially by humans such that state-of-the-art models fail to classify examples correctly.
4.3. Machine Translation
- IWSLT14 (de → en)
- OPUS (OOD)
- Allegra corpus
5. Experimental Setup
5. 1. Model Types
- Sentiment analysis tasks : LSTMs and CNNs
- NLI tasks : fine-tuned RoBERTa_base
- MT tasks : Transformers
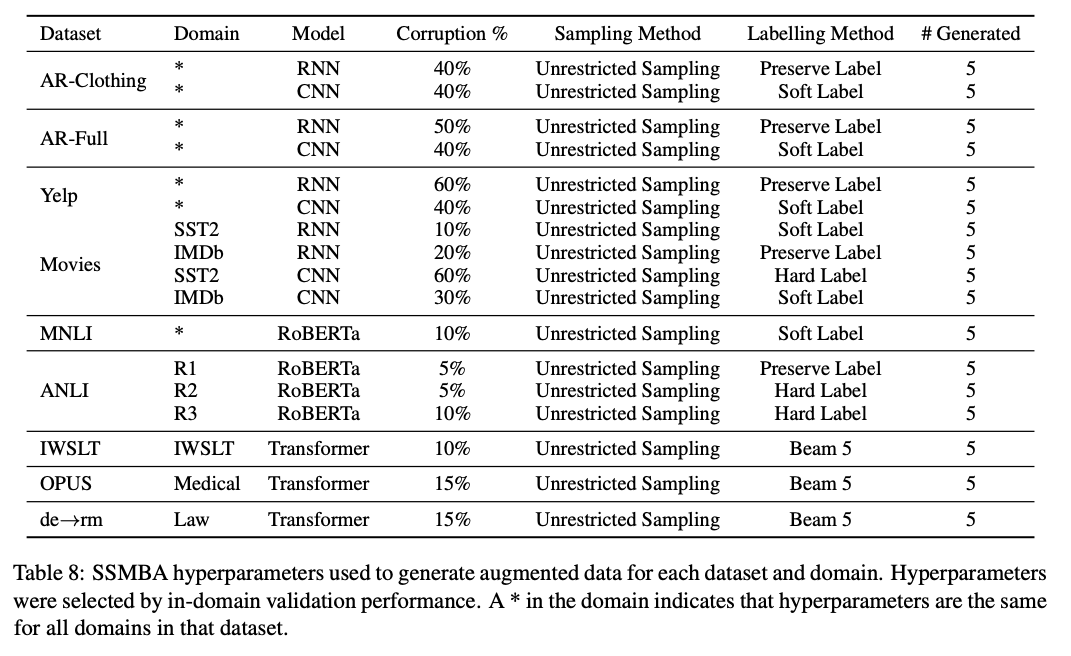
5. 2. SSMBA Settings
- \(q\) : MLM corruption function
- Corruption percentage 는 튜닝
- Sentiment analysis and NLI에서 \(r\) 은 RoBERTa_base 사용
- MT 에서는 pre-trained German BERT model 사용
- 각 인풋 데이터마다 5개의 샘플을 unrestricted sampling 함
- MT 에서는 빔사이즈 5
- Table 8
5. 3. Baselines
Sentiment analysis and NLI tasks
- Easy Data Augmentation (EDA)
- Conditional Bert Contextual Augmentation (CBERT)
- Unsupervised Data Augmentation (UDA) : Back translation
MT tasks
- Word dropout : randomly chooses word in the source sentence to set to zero embeddings
- Reward Augmented Maximum Likelihood (RAML) : noisy target sentences
- SwitchOut : noise function similar to RAML to both the source and target side
5. 4. Evaluation Method
- LSTM / CNN은 10 random seeds
- RoBERTa 는 5 random seeds
- Transformers 는 3random seeds
- 각 도메인에서 학습하고 평가에는 모든 도메인에 대해 평가 (OOD)
6. Results
6. 1. Sentiment Analysis
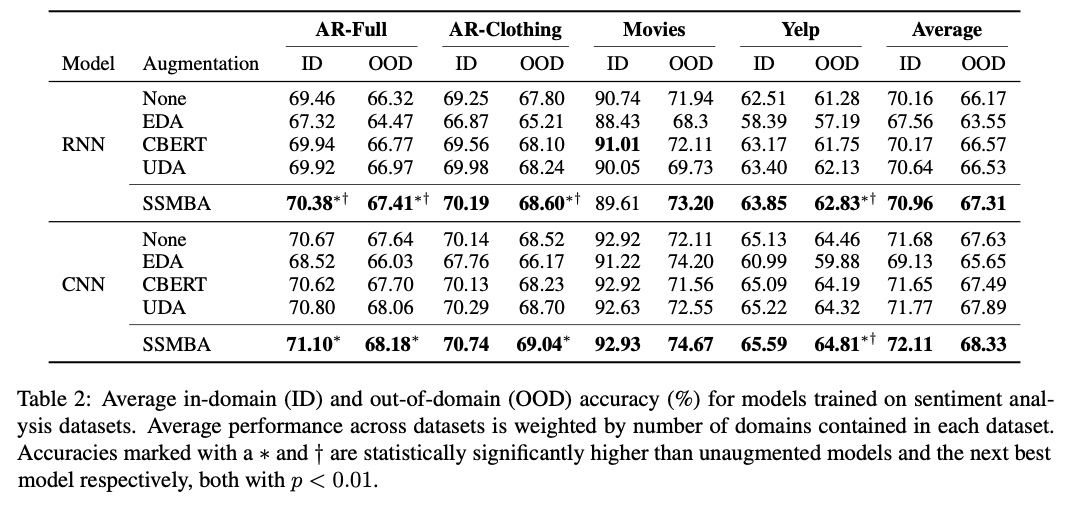
- OOD 데이터에서 SSMBA가 baseline과 다른 augmentation method 보다 좋다.
- In-domain (ID) 데이터에서는 CNN에서는 마찬가지로 좋았고 RNN에서는 Movies 를 제외하고 가장 좋았다.
- OOD 에 대해서 RNN 에서 평균 1.1% 상승 했고 CNN에서는 0.7% 상승했다
- ID 에 대해서 RNN은 0.8% CNN에서는 0.4% 상승 했다.
- 다른 방법론들은 OOD에 대해서 성능이 조금 오르거나 낮아지는 경우도 있었다.
6. 2. Natural Language Inference
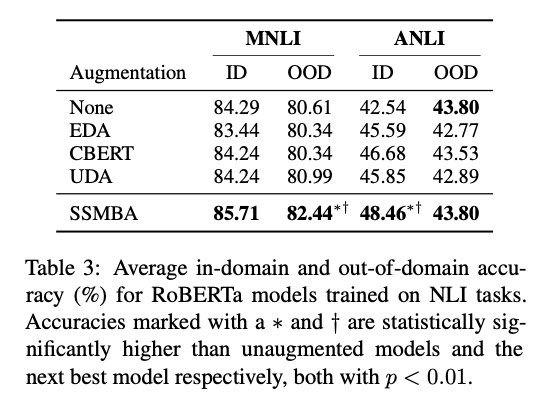
- NLI tasks 에서는 SSMBA가 베이스라인 보다 좋거나, 동일한 성능을 보여준다.
- Baseline이 strong하거나 어려운 task 여도 좋은 성능을 보여줌
6. 3. Machine Translation
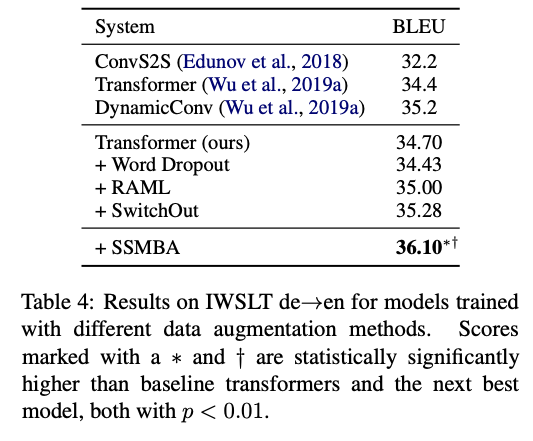
- 다른 방법론들은 성능이 비교적 적게 오르거나 감소하는데 비해 SSMBA는 성능이 많이 오른다.
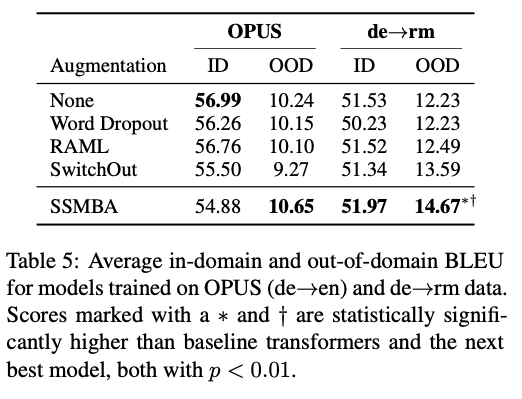
- OOD에 대해서 잘 오르지만 오히려 ID 에서 감소하는 경우도 존재한다.
7. Analysis and Discussion
아래의 특성 및 설정으로 Baby domain within the AR-Clothing dataset에 대한 분석
- 상대적으로 적은 데이터 (25k)
- Number of OOD domains (3)
- Amount of domain shift
- CNN 모델 사용
- 45% Corruption
- Restricted sampling
- Self-supervised soft labeling
- Generating 5 synthetic examples for each training example
7. 1. Training Set Size
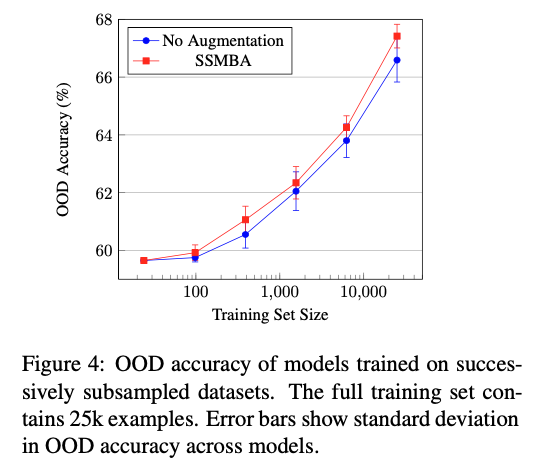
- 작은 데이터셋 일 수록 training distribution을 덜 커버하므로 SSMBA에서 생성된 데이터들은 데이터 매니폴드를 조금밖에 탐색하지 못해 덜 효과적일 것이라고 예상
- 서브샘플링을 하여 서브데이터셋을 만들어서 실험함
- 가장 작은 데이터셋은 24개의 데이터만을 갖고 있음
- 학습 데이터 셋이 100개 이하일 때도 성능 향상을 보이며 대부분의 경우 성능 향상을 보여준다.
7. 2. Reconstruction Model Capacity

- SSMBA는 data manifold를 근사화하는 함수에 의존성이 있기 때문에 더 큰 모델일 수록 더 높은 성능을 기대할 수 있다.
- DistilRoBERTa (82M), RoBERTa_base (125M), RoBERTaLARGE (355M) 을 비교한 결과 비슷한 결과를 보이지만 작은 모델의 경우 성능이 비교적 낮다
7. 3. Corruption Amount
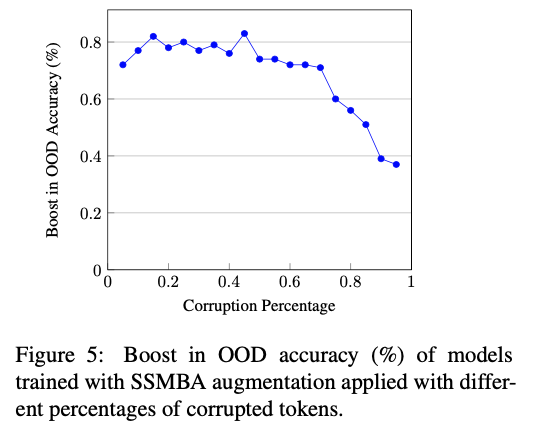
- 경험적으로 Sentiment analysis와 같이 input noise에 민감한 task의 경우 NLI와 같은 더 robust한 task 보다 보다 Corruption이 덜 필요 했다. (?) → 반대로 적었나?
- Empirically, tasks that were more sensitive to input noise, like sentiment anal- ysis, required less corruption than those that were more robust, like NLI.
- Figure 5 에서는 50% 미만 일 때 성능 향상을 보여준다.
- 45% 일 때가 최고치였으며, 그 이후에는 하락하지만 95% 일 때도 baseline 보단 높았다.
- NLI 에서는 많은 노이즈를 줄 경우 baseline 보다 낮아진다.
7. 4. Sample Generation Methods
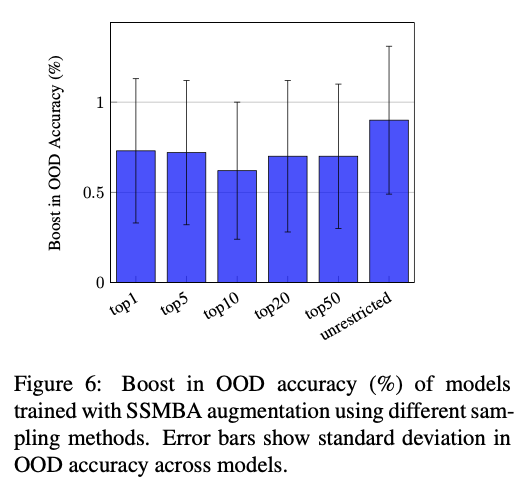
- Top-k sampling의 효과에 대해 조사한다.
- K가 높아질수록 manifold explore를 제한한다.
- Unrestricted의 경우 K가 무제한 (전체 토큰 수)
- Unrestricted의 경우 성능이 가장 좋으며, 아무 제약 없이 manifold를 explore할 수 있을 때 가장 좋은 성능을 시사함.
7. 5. Amount of Augmentation
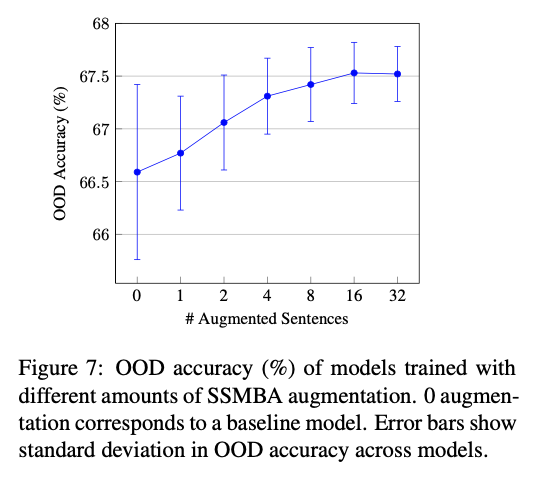
- 데이터셋에 대해서 augmentation amounts 만큼 생성한 걸 5 벌 씩 만들고, 그것을 서로 다른 seed의 10개의 모델로 학습하여 50개 모델 전체에서 OOD 정확도를 평가함.
- DA를 많이 할 수록 성능이 올라가면서 분산도 감소 시킨다.
7. 6. Label Generation
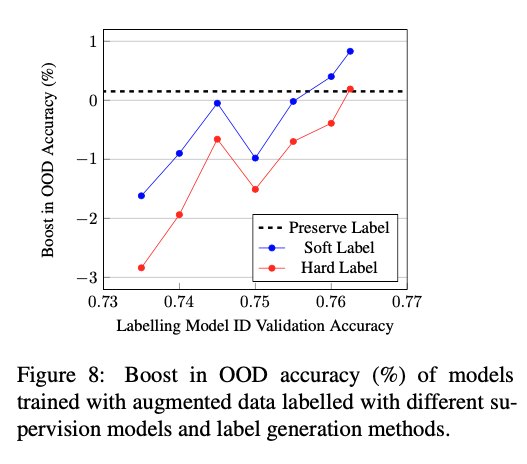
- 생성된 데이터의 label을 결정하는 방법이 3가지가 존재한다.
- 생성을 하기위해 사용된 기존 데이터의 레이블을 그대로 사용 (Label preservation)
- Supervised model을 기존의 데이터셋으로 학습 한 후 생성된 데이터를 통과시켜 one-hot label 을 얻는 방식 (Hard labelling)
- 위와 마찬가지로 하지만, one-hot label을 얻는 것이 아니고 class distribution을 그대로 사용하는 방식 (Soft labelling)
- Soft label의 경우 학습할 때 KL-Divergence를 이용하여 학습
- 성능이 좋지 않은 supervised model을 사용하면 당연히 labelling이 잘 되지 않을 것 이므로 성능이 좋지 않다.
- 하지만 supervised model (classifier)가 성능이 좋아짐에 따라 hard / soft label 의 성능도 올라가게 된다.
- 어느 Threshold를 넘기면 Label preservation 방법보다 성능이 좋아진다.
- Soft labelling이 좋다.
8. Conclusion
In this paper, we introduce SSMBA, a method for generating synthetic data in settings where the underlying data manifold is difficult to characterize. In contrast to other data augmentation methods, SSMBA is applicable to any supervised task, requires no task-specific knowledge, and does not rely on dataset-specific fine-tuning. We demonstrate SSMBA’s effectiveness on three NLP tasks spanning classification and sequence modeling: sentiment analysis, natural language inference, and machine translation. We achieve gains of 0.8% accuracy on OOD Amazon reviews, 1.8% accuracy on OOD MNLI, and 1.4 BLEU on in-domain IWSLT14 de!en. Our analysis shows that SSMBA is robust to the initial dataset size, reconstruction model choice, and corruption amount, offering OOD robustness improvements in most settings. Future work will explore applying SSMBA to the target side manifold in structured prediction tasks, as well as other natural language tasks and settings where data augmentation is difficult.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA