MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
- 8 minsAuthors : Jiaao Chen, Zichao Yang, Diyi Yang
Georgia Tech / CMU
ACL 2020
Paper : https://arxiv.org/pdf/2004.12239.pdf
Code : https://github.com/GT-SALT/MixText
Summary
- Mix-up 기법을 텍스트에 적용한 TMix를 이용
- Unlabeled data에 대해서 augmentation을 위해 Back-translation 사용
- MixText는 TMix와 비전에서의 MixMatch 및 text augmentation 기법들을 모두 합친 프레임워크를 지칭
- AG News, DBpedia, Yahoo, IMDB classification 데이터셋에서 semi-supervised 셋팅과 supervised learning셋팅 모두 비교
개인적 견해
- 비전쪽 아이디어는 항상 뒤늦게 텍스트로 넘어오는 경향이 있는 것 같음
- MixText를 다른 비전 아이디어와 결합하면 좋은 결과가 나올수도 있을 것 같음
- 공개된 코드가 깔끔하지 못함 ☹️
- Paper에 나온 것이 코드에 반영되지 않은 것도 존재
- UDA와 비교가 unfair한 느낌?
Abstract
This paper presents MixText, a semi-supervised learning method for text classification, which uses our newly designed data augmentation method called TMix. TMix creates a large amount of augmented training samples by interpolating text in hidden space. Moreover, we leverage recent advances in data augmentation to guess low-entropy labels for unlabeled data, hence making them as easy to use as labeled data. By mixing labeled, unlabeled and augmented data, MixText significantly outperformed current pre-trained and fined-tuned models and other state-ofthe-art semi-supervised learning methods on several text classification benchmarks. The improvement is especially prominent when supervision is extremely limited. We have publicly released our code at https://github.com/GT-SALT/MixText.
1. Introduction
- 딥러닝은 labeled data가 많이 필요하지만 종종 data가 부족한 경우 overfitting이 발생함
- labeled data를 만드는것은 시간과 비용이 많이 소모하며 이러한 문제는 Neural network를 새로운 환경이나 real-world problem에 적용하기 어려움
- 그에 반해 Unlabeled data는 얻기 쉬우며 labeled data와는 다른 task에 사용되어서 많이 주목을 받았음
- Text classification에 semi-supervised learning을 적용한 이전 연구들은 아래와 같이 분류를 할 수 있음
- Variational Auto Encoder (VAE) 기반
- Self-training 기반 (Pseudo-label)
- Consistency training with adversarial noise or data augmentation (UDA)
- Large scale pretraining with unlabeld data, then finetuning with labeled data (BERT)
- 이러한 다양한 연구들이 잘 되었음에도 불구하고, labeled data와 unlabeled data가 서로 supervision 하는 방식은 사용되지 않고 따로 사용함
- 그러므로 대부분의 semi-supervised learning의 경우 labeled data가 제한적인 상황에서 unlabeled data가 충분하여도 overfitting이 발생함
- 이러한 문제점을 해결하기 위해 new data augmentation method인 TMix를 제안 (Mixup에서 영감을 받음) Figure 1.은 TMix의 전체적인 모습
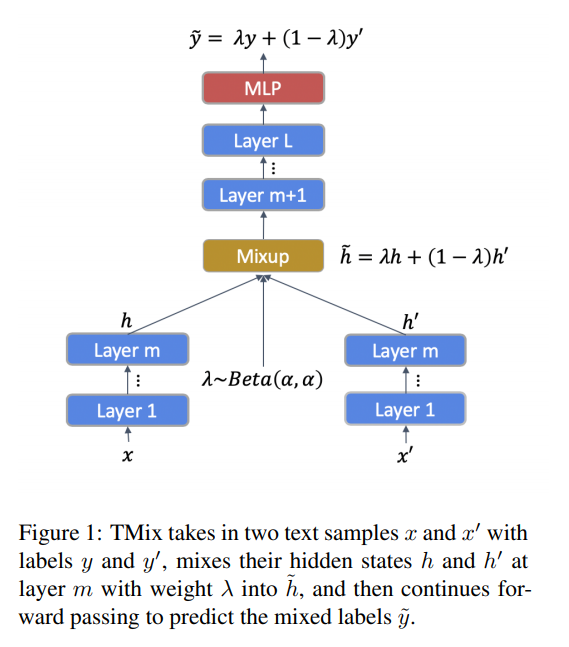
- TMix는 두개의 서로다른 text instances 를 model의 hidden space 상에서 interpolation을 하는 기법
- hidden space 상에서 합치게 될 경우 continuos 하므로 무한한 샘플을 만들수 있으며, 이로인해 overfitting이 해결 될 수 있음
- TMix를 바탕으로 Text classification을 위한 Semi-supervised learning method 인 MixText를 제안
- MixText에서는 labeled data와 Unlabeled data의 관계를 모델링하여 이전 연구의 한계를 극복
- Unlabeled data에 대해 label guessing을 함
- TMix를 사용하여 labeled data와 unlabeled data를 interpolation 함
- Unlabeled data를 활용하기 위해 back-translation 이후 self-target prediction, entorpy minimization, consistency regularization 을 사용함
2. Related Work
2.1. Pre-training and Fine-tuning Framework
: GPT, BERT 와 같은 PLM 모델에 대해 소개
2.2. Semi-Supervised Learning on Text Data
: VAE, Adversarial training, Virtual Adversarial Training (VAT), Unsupervised Data Augmentation (UDA) 등을 소개
2.3. Interpolation-based Regularizers
: MixUp 기반의 방법들을 사용한 논문들 소개
2.4. Data Augmentations for Text
: 동의어 치환, 랜덤 삭제 등 EDA 또는 Back translation 등 다양한 Augmentation 기법 소개
3. TMix
- Mixup을 Text domain에서 사용 하는 방법 제안
- Mixup
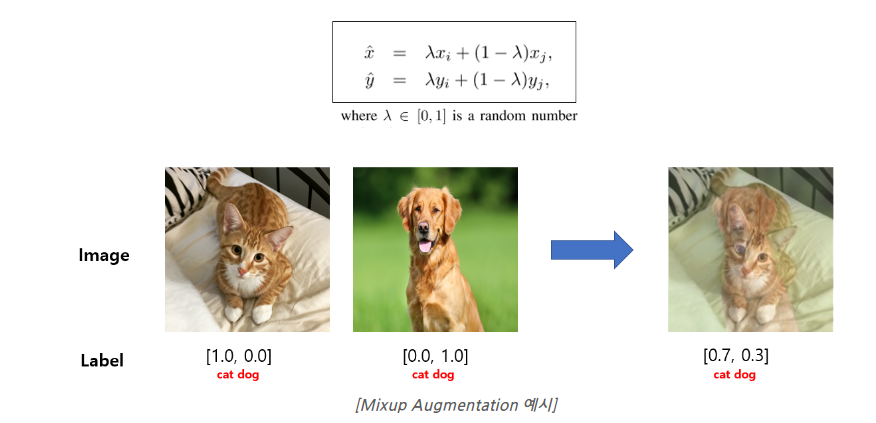
- 이러한 방법은 Discrete token을 가지는 Text에서 그대로 적용을 하지 못함
- 따라서 “interpolation in textual hidden space” 을 함
- 아래 Figure를 보면 직관적으로 이해가 가능함
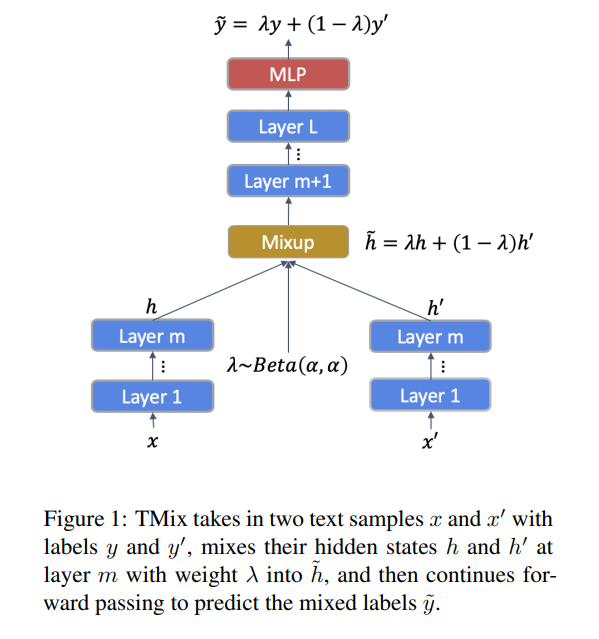
-
위의 Figure를 아래와 같은 식으로 정리 할 수 있음
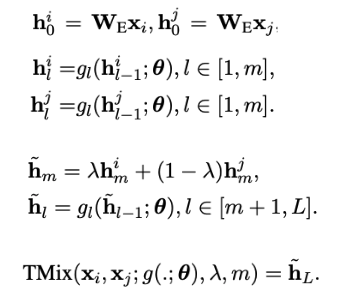
-
Interpolation 비율인 \(\lambda\) 는 기존 MixUp 방식과 동일하게 설정하며, 여기서 \(\alpha\)는 hyper-parameter
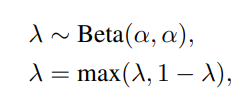
- 또한 여기서는 12-layer BERT-base 를 바탕으로 실험을 하였는데, 어느 layer에서 mixup을 할 것인지도 의사결정을 해야함
- “What does BERT learn about the structure of language” 논문에서 BERT는 각 layer마다 학습하는 것이 다르다고 함
- Syntactic and semantic information을 잘 포함하는 {7, 9, 12} layers set에서 랜덤으로 선택하여 사용
- Downstream task (text classification)에서의 Supervision loss는 다음과 같음
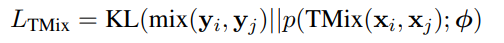
4. Semi-supervised MixText
MixText는 Text semi-supervised learning framework 이고, TMix는 Data Augmentation 기법이므로 혼동하지 말아야함
Labeled data와 Unlabeled data를 모두 사용하여 classifier를 학습하도록 하는 것이 목적
이러한 학습에는 Unlabeled data에 대하여 label을 붙여주는 과정이 필요
해당 과정에서 Data augmentation, label guessing, entropy minimization 사용
전체 Flow는 다음과 같음
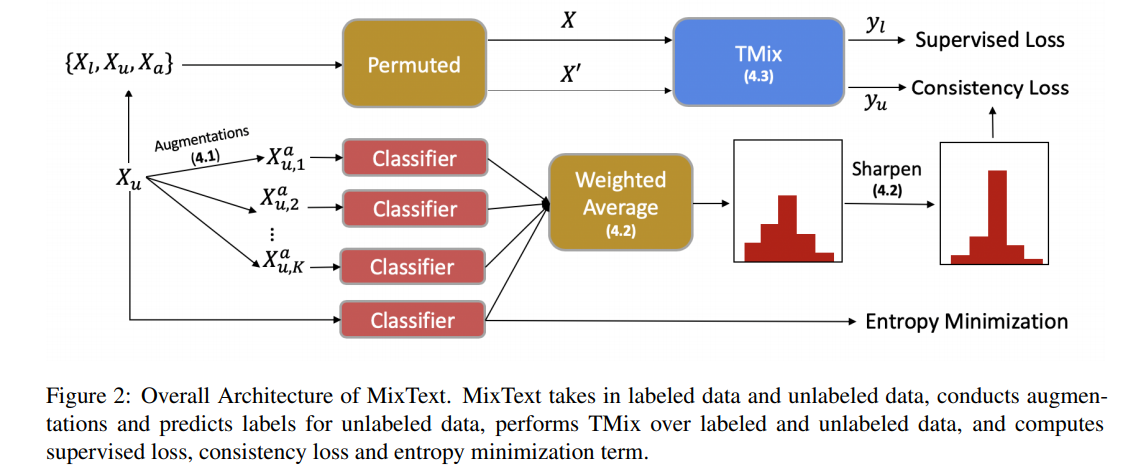
4.1. Data Augmentation
- Back-translation 을 이용하여 Unlabeled data에 대해 서로 다른 intermediate language로 \(K\)개를 생성
- Back-translation 을 할 때 beam search 대신 temperature scaling을 하면서 random sampling을 하였음
4.1. Label Guessing
- Unlabeled data 와 Augmented data 에 Virtual label을 붙여주기 위해 Label Guessing 이라는 방법을 사용한다
- Original data와 augmented data에 대해서 predicted result를 weighted average
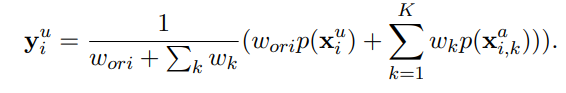
- 그 후 Weighted average 한 값이 uniform 해지는 것을 방지하기 위해서 sharpening 을 함
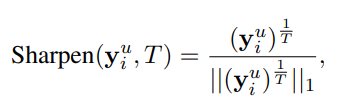
4.3. TMix on Labeled and Unlabeled Data
- 앞에서 만들어진 Unlabeled data with guessed label , Augmented data with guessed label 을 통해 TMix를 다음과 같은 방법으로 진행한다.
- Labeled data, unlabeled data, unlabeled augmentation data 를 모두 더해 super set \(X\)를 만들고 마찬가지로 label 도 더해서 super set \(Y\)를 생성
- 학습 과정에서 X, Y 에서 랜덤으로 두 데이터를 샘플링하여 TMix Loss를 얻을 수 있음
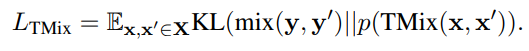
- 이러한 TMix Loss는 두가지 방법으로 얻어질 수 있는데
- \(x\) 가 Labeled data로 샘플링 되었을 때 Labeled data에 대해 Supervised loss
- \(x\) 가 augmented data or unlabeled data로 샘플링 되었을 때 Augmented data와 Unlabeled data에 대해 Consistency loss
- 실제 코드 상으로는 랜덤 조합으로 학습하기 때문에 배치 내에서 분할하여 각 loss를 구해서 합한다
4.2. Entropy Minimization
- Unlabeled data에 대하여 model이 label guessing을 잘하도록 prediction probability on unlabeled data 의 entropy를 minimize 하도록 self-training loss를 추가함
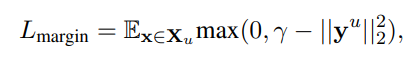
-
해당 Loss도 실제 코드상에서는 사용이 안되는 것 같음
-
최종적으로 MixText Loss는 다음과 같음
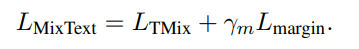
5. Experiments
5.1. Dataset and Pre-processing
- Dataset : AG News, DBPedia, Yahoo! Answer, IMDB
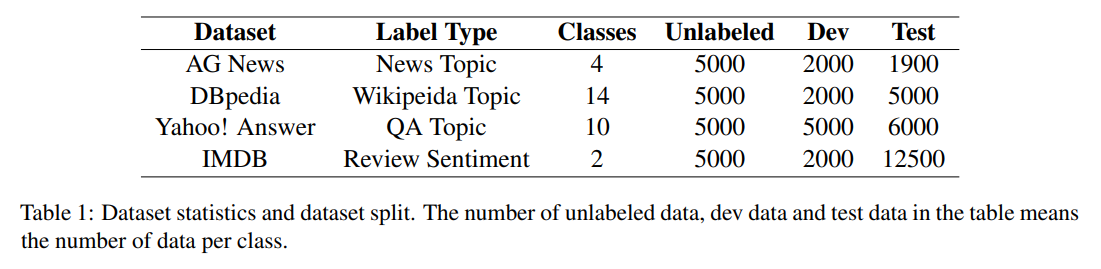
5.2. Baselines
- VAMPIRE (VAriational Methods for Pretraining In Resource limited Environments)
- BERT (BERT: Pre-training of deep bidirectional transformers for language understanding)
- UDA (Unsupervised data augmentation for consistency training)
5.3. Model Settings
We used BERT-based-uncased tokenizer to tokenize the text, bert-based-uncased model as our text encoder, and used average pooling over the output of the encoder, a two-layer MLP with a 128 hidden size and tanh as its activation function to predict the labels. The max sentence length is set as 256. We remained the first 256 tokens for sentences that exceed the limit. The learning rate is 1e-5 for BERT encoder, 1e-3 for MLP. For α in the beta distribution, generally, when labeled data is fewer than 100 per class, α is set as 2 or 16, as larger α is more likely to generate λ around 0.5, thus creating “newer” data as data augmentations; when labeled data is more than 200 per class, α is set to 0.2 or 0.4, as smaller α is more likely to generate λ around 0.1, thus creating “similar” data as adding noise regularization. For TMix, we only utilize the labeled dataset as the settings in Bert baseline, and set the batch size as 8. In MixText, we utilize both labeled data and unlabeled data for training using the same settings as in UDA. We set K = 2, i.e., for each unlabeled data we perform two augmentations, specifically German and Russian. The batch size is 4 for labeled data and 8 for unlabeled data. 0.5 is used as a starting point to tune temperature T. In our experiments, we set 0.3 for AG News, 0.5 for DBpedia and Yahoo! Answer, and 1 for IMDB.
5.4. Results
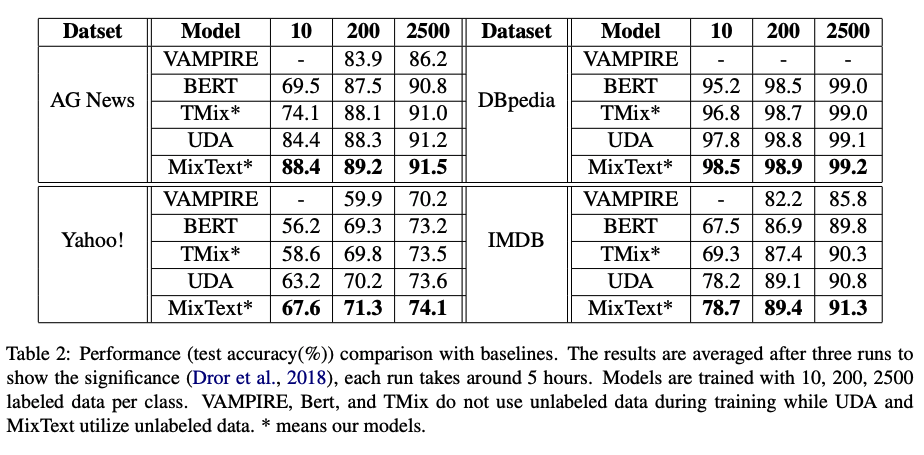
- Performance comparison with baselines
- MixText가 가장 좋다고 한다… 무려 모든 데이터셋에 대해서.
- Varying the Number of Labeled Data
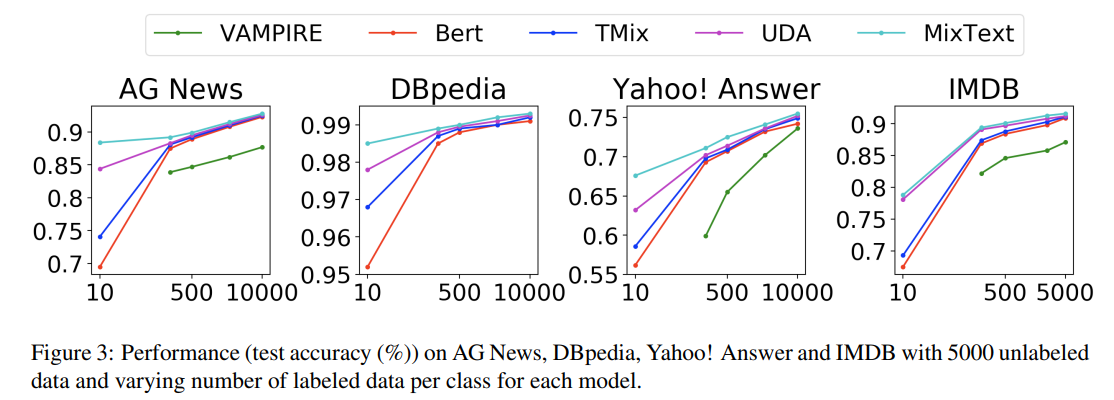
- Varying the Number of Unlabeled Data
- unlabeled data를 늘리면 성능도 향상
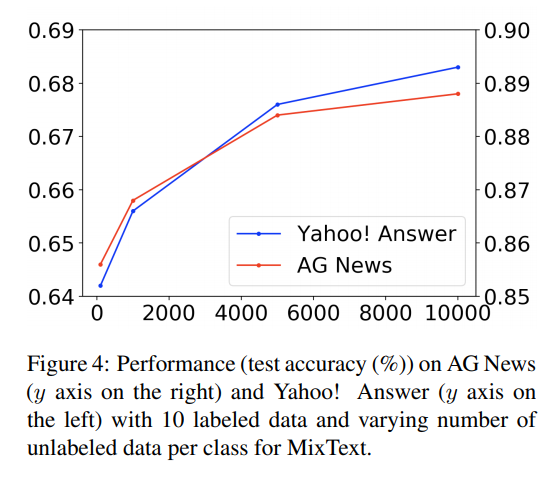
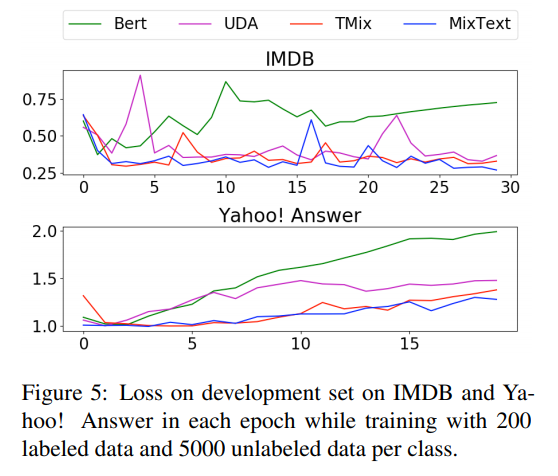
- Loss on Development Set
- 비교적 다른 방법들 보다 Development Set 에서의 overfitting이 적다고 주장
5.5. Ablation Studies
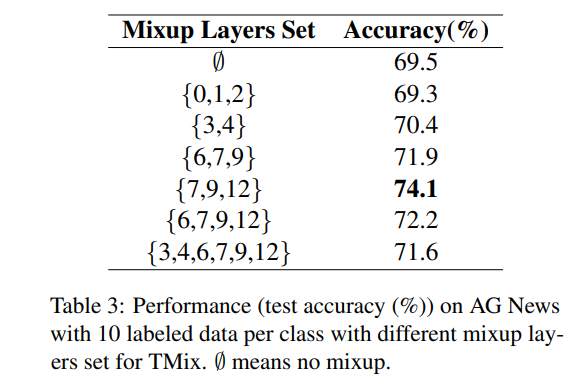
- Different Mix Layer Set in TMix
- 실험 결과 syntactic과 semantic 정보를 많이 포함하는 쪽에서 성능이 잘나옴
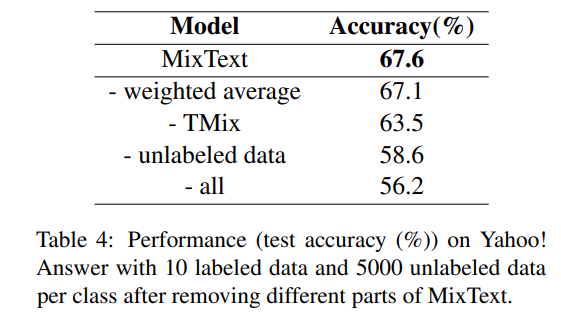
- Remove Different Parts from MixText
- 당연하게 unlabeled data 가 가장 영향력이 크다.
- weighted average 는 생각보다 영향력이 적음.
6. Conclusion
To alleviate the dependencies of supervised models on labeled data, this work presented a simple but effective semi-supervised learning method, MixText, for text classification, in which we also introduced TMix, an interpolation-based augmentation and regularization technique. Through experiments on four benchmark text classification datasets, we demonstrated the effectiveness of our proposed TMix technique and the Mixup model, which have better testing accuracy and more stable loss trend, compared with current pre-training and fine-tuning models and other state-of-the-art semi-supervised learning methods. For future direction, we plan to explore the effectiveness of MixText in other NLP tasks such as sequential labeling tasks and other real-world scenarios with limited labeled data.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA