Meta-tuning Language Models to Answer Prompts Better
- 8 minsAuthors : Ruiqi Zhong, Kristy Lee, Zheng Zhang, Dan Klein - Berkeley
Arxiv 2021
Paper : https://arxiv.org/pdf/2104.04670.pdf
Code : -
Summary
- Unseen tasks에도 generalization이 되는 meta-tuning을 제안함
- Meta-tuning에 사용되는 데이터셋을 수집하고 제작
- 기존 모델 UnifiedQA에 비해 좋은 성능을 보임
개인적 견해
- 다양한 데이터셋에 generalize된 prompt로 fine-tuning 하는 느낌으로 전체적으로 임팩트가 부족함
- GPT-3 모델에 대해서도 meta-tuning을 하고 In-context learning과의 비교가 있었으면 좋았을 듯 함
Abstract
Large pretrained language models like GPT- 3 have acquired a surprising ability to perform zero-shot classification (ZSC). For example, to classify review sentiments, we can “prompt” the language model with the review and the question “Is the review positive?” as the context, and ask it to predict whether the next word is “Yes” or “No”. However, these models are not specialized for answering these prompts. To address this weakness, we propose meta-tuning, which trains the model to specialize in answering prompts but still generalize to unseen tasks. To create the training data, we aggregated 43 existing datasets, annotated 441 label descriptions in total, and unified them into the above question answering (QA) format. After meta-tuning, our model outperforms a same-sized QA model for most labels on unseen tasks, and we forecast that the performance would improve for even larger models. Therefore, measuring ZSC performance on non-specialized language models might underestimate their true capability, and community-wide efforts on aggregating datasets and unifying their formats can help build models that understand prompts better.
1. Introduction
- GPT-2와 GPT-3에서 Prompt를 통해 Zero-Shot Classification (ZSC)에 대한 좋은 성능을 얻음
- e.g.) Prompt : “Review: This movie is amazing! Positive Review ? ___ “ → “Yes” or “No”
- 최근에 많은 연구들은 ZSC와 같은 zero-shot task를 Language model이 더 잘 답할 수 있도록 더 나은 prompt를 찾는 방법에 중점을 둠
- Large LM에서의 prompt에 대한 답변에 맞춰져서 학습되지 않고 일반적인 MLM 방식이나 AR 방식으로 학습이 되어 prompt에 대한 답변은 하나의 추가 부산물로 볼 수 있음.
-
하지만 당연하게 task에 대한 학습을 한 경우 더 좋은 성능을 얻을 수 있으며, 그에 대한 예로 T5 기반 General QA 모델인 UnifedQA는 200배 작은 모델 사이즈로 SST-2에 대한 zero-shot classification 성능이 GPT3의 성능보다 좋음 (92% / 80%)
- 본 연구에서는 ZSC를 위한 모델을 학습함. 이를 위해서 아래와 같은 방법을 사용함
- 다양한 분류 작업을 하나의 포맷으로 통합
- 학습을 위해 데이터셋과 레이블 수집 (section 2)
- Dataset의 datasets (meta-dataset)에 대해 fine-tuining 하여 Zero-shot learning에 대해 학습하고 이러한 방법을 meta-tuning 이라고 정의함
- 제안하는 방법은 PLM을 통해 fine-tuning 없이 ZSC하는 것과 specific task에 대해 fine-tuning을 하는 방법 사이에 존재함
- ZSC 모델을 만들고 new unseen tasks에 대해서도 일반화 할 수 있음
- 본 연구에서는 Binary classification에 포커싱하며 “Yes” / “No” 포맷으로 변경하며 레이블 정보는 Question (prompt) 를 통해 모델에 제공함
- 이러한 포맷으로 43개의 다양한 소스 (Kaggle, SemEval, HuggingFace, …)로 부터 데이터를 수집했고 이러한 데이터들은 Hate speech detatction, question categoraization, sentiment classification 등을 포함함
-
데이터셋은 204개의 label과 441개의 manually annotated label description 로 이루어짐
- ZSC 평가를 위해 unseen task를 정의해야 하는데 이 unseen task는 학습에 사용한 데이터셋과 유사하지 않은 데이터셋을 의미함
- 각 label description에 대해 AUC-ROC score를 UnifiedQA 모델과 비교 함
- 대부분의 경우 메타 튜닝된 모델이 더 우수하고 더 큰 모델에서도 잘 작동할 것이라고 예상됨
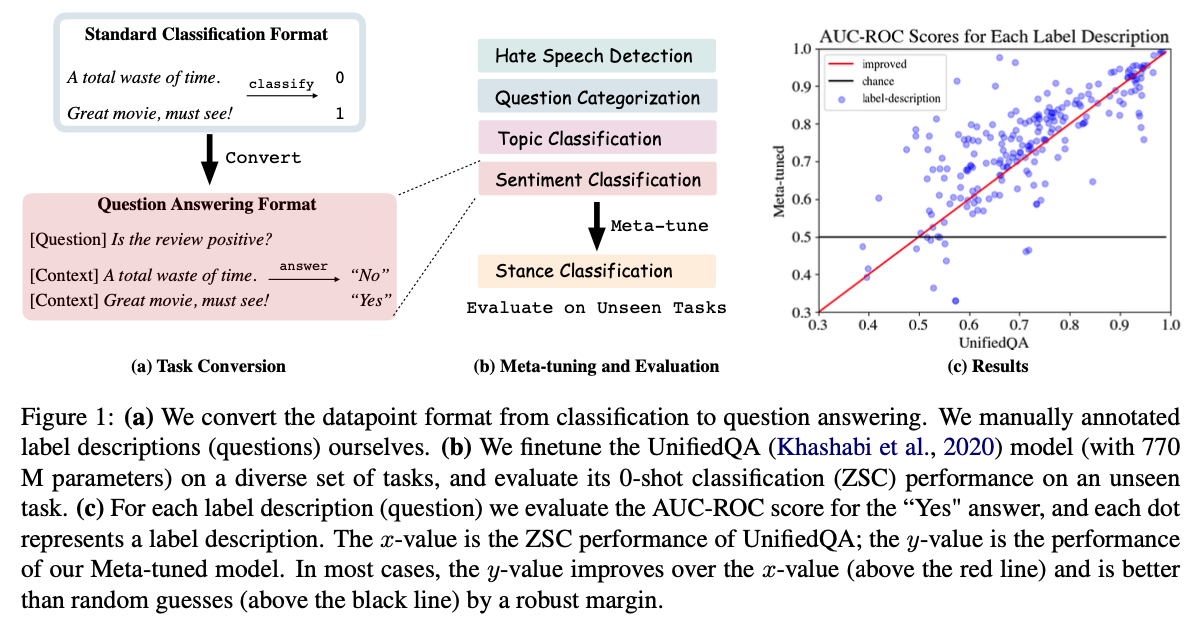
2. Data
- 다양한 classification datasets을 수집하여 “Yes” / “No” question answering format으로 변환하여 형식을 통일함
- 데이터셋의 일부 유사한 데이터셋을 그룹화하여 evaluation에서 unseen tasks로 간주한다.
Gathering Classification Datasets
- Kaggle, Huggingface, SemEval, and other papers에서 영어 classification dataset 데이터 수집하였고 깨끗한 데이터인지 직접 조사 필터링함
- Sentiment classification, topic classification, grammaticality judgement, paraphrase detection, detecting definition 와 같은 tasks 존재
- 해당 데이터들은 academic papers, reviews, tweets, posts, messages, articles, and text books로 구성됨 (Appendix A).
Unifying the Dataset Format
- 각 classification dataset에 “Yes” / “No” QA format으로 변환하고 question에 label information을 제공함
- 각 label에 대해서 1 ~ 3개의 annotation을 달아줌
- 저자 3명이 204개의 label에 대해 441개의 질문에 직접 annotation을 달았음
- 구체적인 예는 Figure 2, Figure 3을 참조
- 일부 데이터에서는 수천개의 labels이 존재하는데 이 경우 template을 이용하여 automatically 하게 label description을 생성하고, 그러한 것들은 evalutation에서 제외한다.


Grouping Similar Tasks
- Meta-tuning의 목표는 Training task와 다른 task 들에 대해서도 모델이 일반화된 성능을 갖도록 하는 것
- 따라서 테스트시 메타 튜닝 단계에서 사용된 데이터셋 뿐만 아니라 비슷한 데이터셋도 제거함
- 데이터셋이 동일한 task를 수행하는지는 주관적이고 보편적으로 정의하기 어려움
- 극단적인 경우 대부분의 데이터셋은 label spaces와 input distributions이 다르므로 다른 task라고 말할 수 있지만 모든 데이터셋이 Question answering task로 볼 수 있기 떄문에 동일한 task로 간주 할 수도 있음.
- 이러한 문제를 해결하기 위해 데이터셋의 속성을 설명하는 set of tags 을 생성함.
- Set of tags는 domain classificationk, article, emotion, social-media 등을 포함함 (Appendix B)
- 그런 다음 두 데이터셋이 동일한 set of tags에 존재할 경우 동일한 task로 정의하여 training data와 test data로 나누어 지는것을 막는다. (Figure 4)
- Unseen splits과 annotated label descriptions은 릴리즈될 예정

3. Model
Notation
- “{fine- tuning task}({model size})” 형식으로 표현
- For example, a UnifiedQA model initialized with the 770 Million parameter T5 model will be denoted as “QA(770M)”. If it is meta-tuned, we denote it as “Meta(770M)”.
- UnifiedQA : a single pre-trained QA system that works well on and generalizes to datasets with different formats, while performing on par with state-of-the-art dedicated systems tailored to each dataset.
Architecture
- UnifiedQA (2020) 의 방식과 동일하게 Seperation token을 이용하여 Context 와 question을 합침
- 합쳐진 문장을 T5 인코더에 입력으로 사용하여 디코더에서 첫번째 토큰으로 부터 “Yes” / “No” 토큰에 대해서만 확률값을 구함
Meta-tuning
- 다양한 데이터 셋에 대하여 uniformly at random selection을 하고, 해당 데이터셋의 label description에 대해서도 uniformly at random selection을 한 후, 50% 확률로 “Yes” / “No” 로 답하는 textual input을 택한다.
- Overfitting을 방지하기 위해 한번 사용된 label description과 textual input 조합에 대해 다시 사용하지 않는다
- Batch size 32 / 5000 steps
4. Results
- ZSC 의 test dataset의 각 label descriptions에 대한 AUC-ROC score를 측정
- “Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach” 에서 제안된 Three benchmark datasets에 대한 성능 측정
- 두 가지 평가에서 동일한 두가지 결론이 도출 됨
- Meta(770M) 은 QA(770M) 보다 성능이 높음 - Meta-tuning이 효과적임
- Meta(770M) 은 Meta(220M) 보다 성능이 높음 - 큰 모델에서 더 효과적임
4.1. Description-wise AUC-ROC
- 산점도의 각 점은 label description을 나타내고 x 값은 한 모델의 AUC-ROC score를 나태나고 y 값은 다른 한 모델의 score를 나타낸다.
- 서로 다른 데이터셋에 대한 모델의 성능을 단일 숫자로 측정하지 않고 각 데이터셋끼리만 비교
- 데이터셋 A와 데이터셋 B가 똑같이 중요하더라도 (0.6, 0.9) / (0.75, 0.8) 이 어떤게 더 나은지 확실하지 않음
- Aggregate statistics는 하위 수준의 정보를 알수 없게됨
- Figure 5. 를 보면 대부분의 점은 빨간선 (y=x) 위에 존재하므로 대부분의 label에 대해 크고, meta-tuned 모델 일 수록 좋음
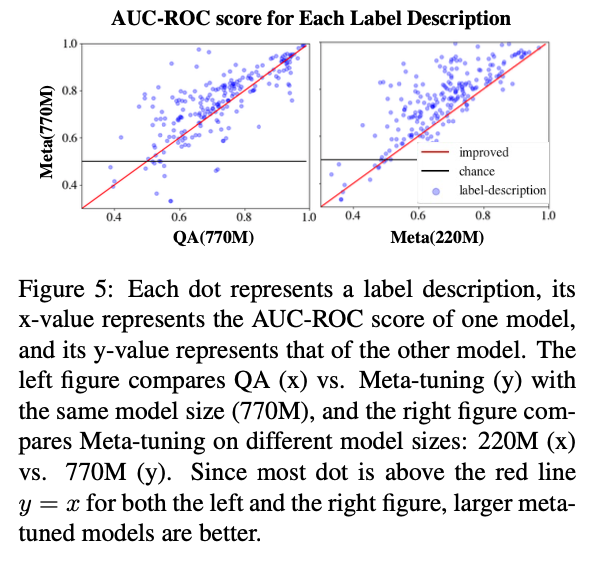
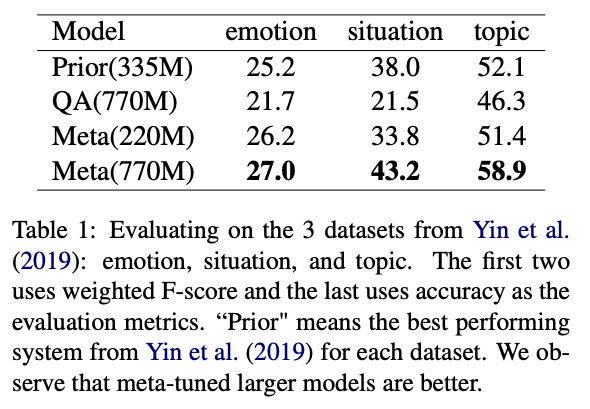
4.2. Benchmarking with Yin et al. (2019)
- “Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach”
- Prior : 위키피디아에 대한 auxillary training objectives 사용한 RoBERTa-Large 기반의 앙상블 모델
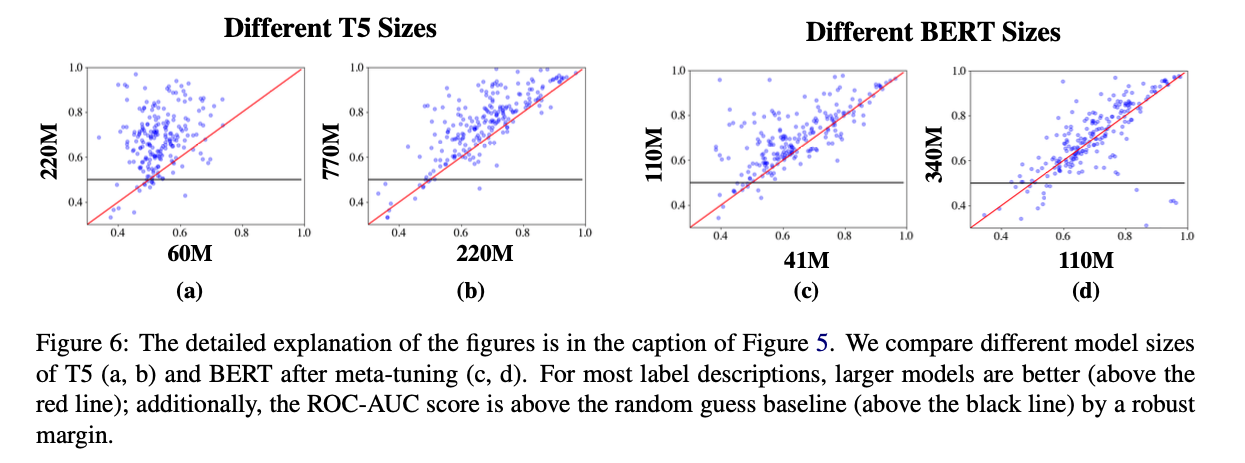
4.3 Robustness Checks
- Model size
- Model architecture / Dataset
5. Discussion
Meta-tuning as a Probe
- GPT-3와 같은 Large scale PLM에 대해서 zero-shot In-context learning을 하지 않고 이러한 meta-tuning을 사용하여 성능 향상을 할수 있음
Aggregating and Unifying Datasets
- 연구의 주요 bottleneck은 많은 데이터셋을 모으는 것이고 이 과정은 어려운 점이 있음
- 새로운 task를 위해 NLP 관련 문헌들을 광범위하게 브레인스토밍하고 검토해야함
- 서로 다른 데이터셋을 서로 다른 포맷으로 인코딩 하는 과정
- 데이터셋 품질에 대한 검토
- 이러한 것들을 제공해주는 플랫폼이 있었다면 훨씬 쉬웠을 것
Annotating Prompts
- 세명의 저자가 label descriptions을 달았음.
- Machine learning과 NLP를 다루는 Computer science 전공이므로 Zero-shot classification application의 최종 사용자 집단을 대표하지 않을 수 있으며 이에 대한 bias가 생겼을 수 있음.
- Target user distribution와 일치하도록 프롬프트에 주석을 추가하는 것은 중요한 연구 방향이 될 수 있음.
Optimizing Prompts
- 메타 튜닝된 모델이 사용된 프롬프트 (label description)에 대해 잘 학습되어 있어도 다양한 프롬프트에 대해 성능이 다르게 나타날 수 있음
- 예를 들어 stance classification dataset에서의 비슷한 의미의 label descriptions에 대해 후자가 더 좋은 성능을 보여준다.
- “Does this post support atheism?”
- “Is the post against having religious beliefs?”
- “atheism” (무신론) 과 같은 추상적인 개념을 잘 이해하지 못하기 때문이라고 추측함
Other Extensions
- Binary classification이 아닌 multi-label classification으로 확장 될 수 있음
- Few-shot classification으로 확장될 수 있으며 이를 위해서 더 큰 context window와 computation resources가 필요함
- Sequence generation tasks로도 확장이 가능하며 이를 위해서는 많은 sequence generation tasks dataset을 수집해야함
6. Ethics
논문 참고

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA