Industry Scale Semi-Supervised Learning for Natural Language Understanding
- 4 minsAuthors : Luoxin Chen, Francisco Garcia, Varun Kumar, He Xie, Jianhua Lu - Alexa AI (amazon)
NAACL2021
Paper : https://www.aclweb.org/anthology/2021.naacl-industry.39.pdf
Code : -
Problem Definition
SSL techniques in “real-world” NLU applications is still in question.
- Having high quality labeled data is the key to achieve improving accuracy.
- However, obtaining human annotation is an expensive and time-consuming process.
- A common practice to evaluate SSL algorithms is to take an existing labeled dataset and only use a small fraction of training data as labeled data, while treating the rest of the data as unlabeled dataset.
- Such evaluation, often constrained to the cases when labeled data is scarce, raises questions about the usefulness of different SSL algorithms in a real-world setting.
- How much unlabeled data should we use for SSL and how to select unlabeled data from a large pool of unlabeled data?
- Most SSL benchmarks make the assumption that unlabeled datasets come from the same distribution as the labeled datasets.
- This assumption is often violated as, by design, the labeled training datasets also contain synthetic data, crowd-sourced data to represent anticipated usages of a functionality, and unlabeled data often contain a lot of out of domain data.
Contribution
- Design of a production SSL pipeline which can be used to intelligently select unlabeled data to train SSL models.
- Experimental comparison of four SSL techniques including, Pseudo-Label, Knowledge Distillation, Cross-View Training, and Virtual Adversarial Training in a real-world setting using data from Amazon Alexa.
- Operational recommendations for NLP practitioners who would like to employ SSL in production setting.
Methods
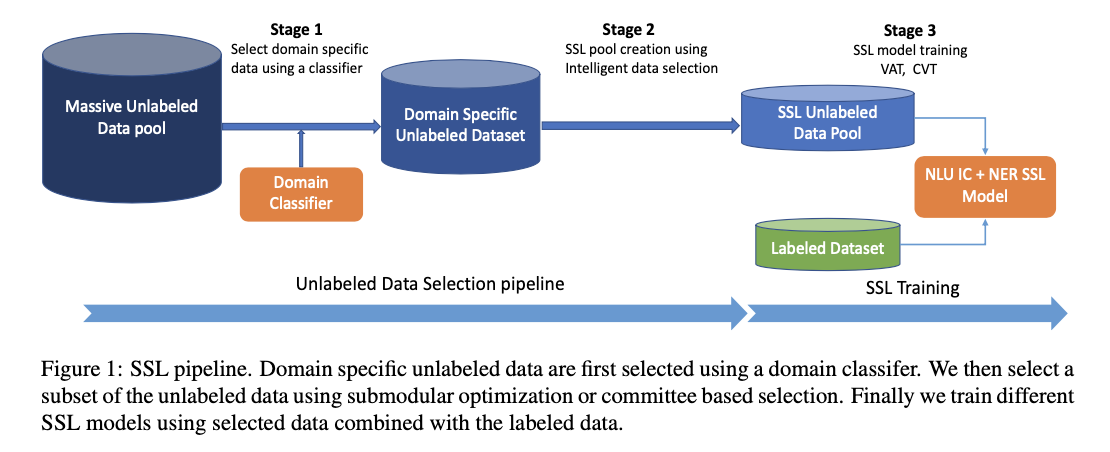
Data Selection Approaches
- First uses a classifier’s confidence score to filter domain specific unlabeled data from a very large pool of unlabeled data, which might contain data from multiple domains.
- Training a binary classifier on the labelled data, and use it to select the in-domain unlabelled data.
- Using Confidence scire 0.5 as the threshold for data selection.
-
The goal of the second stage filtering is to find a subset of data which could result in better performance in SSL training.
Selection by Submodular Optimization
(Paper : Submodularity for data selection in machine translation)
- For SSL data selection, we use 1-4 n-gram as features and logarithm as the concave function.
- We filter out any n-gram features which appear less than 30 times in Dl ∪ Du.
- The algorithm starts with Dl as the selected data and chooses the utterance from the candidate pool Du which provides maximum marginal gain.
Selection by Committee
- To detect data points on which the model is not reliable, we train a committee of n teacher models (we use n = 4 in this paper), and compute the average entropy of the probability distribution for every data point.
- Compute the average entropy of the predicted label distribution of x.
- We then identify an entropy threshold with an acceptable error rate for mis-annotations (e.g., 20%) based on a held-out dataset.
Semi-Supervised Learning Approaches
- Pseudo-labeling
- Knowledge Distillation
- Virtual Adversarial Training
- Cross-View Training (CVT) [LINK]
Results
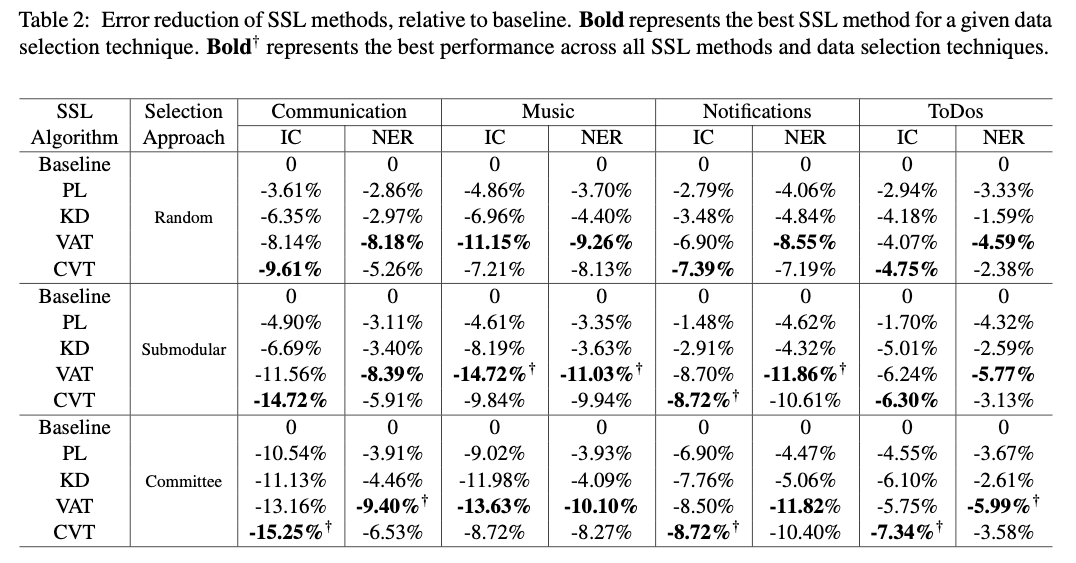
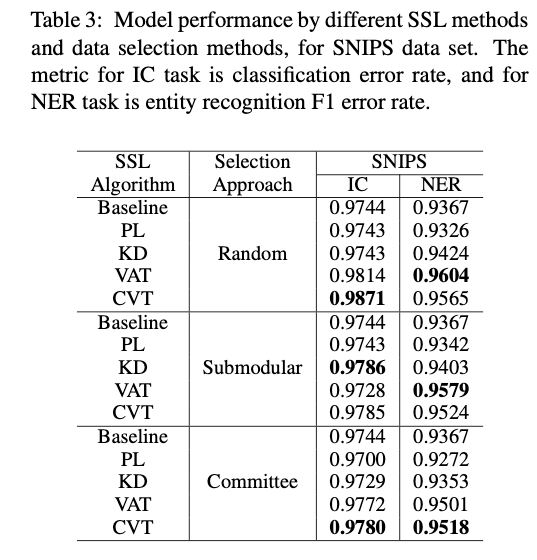
Diversity of Selected Data
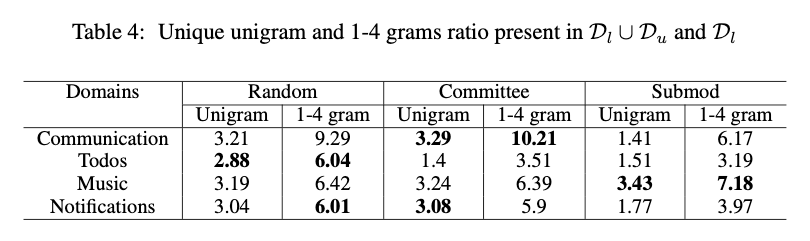
- Measuring the diversity of the selected data by computing the unique n-gram ratio present in Dl ∪ Du and Dl data.
- We observe that a diverse SSL pool does not necessarily lead to better performance.
- This result highlights that simply optimizing for token diversity is not enough for improving SSL performance.
Recommendations
- Prefer VAT and CVT SSL techniques over PL and KL.
- Use data selection to select a subset of unlabeled data.
- Recommend Submodular Optimization based data selection in light of its lower cost and similar performance to committee based method.
- Optimizing data selection, when unlabeled data pool is of a drastically different distribution from the labeled data, remains a challenge and could benefit from further research.
Related Paper
Self-training Improves Pre-training for Natural Language Understanding [LINK]

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA