How Many Data Points is a Prompt Worth?
- 7 minsAuthors : Teven Le Scao, Alexander M. Rush / Hugging Face
Arxiv 2021
Paper : https://arxiv.org/pdf/2103.08493.pdf
Code : -
Summary
- Prompt 자체만으로도 많은 양의 데이터의 효과를 갖음
- PET과 같은 prompt based model의 경우 데이터 효율을 높여줌
- verbalizer에 큰 영향을 받지 않음
- prompt들이 어느정도 잘 설계 되어 있다면 그 prompt 간의 성능은 크게 차이 나지 않음
개인적 견해
- 앞으로는 head-based model보다 prompt-based 모델이 사용될 것이고 그러기 위해서는 prompt engineering에 관한 연구가 필요할 것이다.
Abstract
When fine-tuning pretrained models for classification, researchers either use a generic model head or a task-specific prompt for prediction. Proponents of prompting have argued that prompts provide a method for injecting task-specific guidance, which is beneficial in low-data regimes. We aim to quantify this benefit through rigorous testing of prompts in a fair setting: comparing prompted and head-based fine-tuning in equal conditions across many tasks and data sizes. By controlling for many sources of advantage, we find that prompting does indeed provide a benefit, and that this benefit can be quantified per task. Results show that prompting is often worth 100s of data points on average across classification tasks.
1. Introduction
- Classification에 대한 main paradigm은 PLM을 fine-tuning 하는 방식이였음
- 최근에는 다른 방법론이 떠오르고 있음
- GPT2 / GPT3 처럼 AR 하게 생성하는 방법
- Cloze task (MLM) 을 이용하는 방법
- 이러한 방식은 custom prompt를 사용할 수 있다고 다른 논문에서 주장하고 있음
- 이 방식은 zero-shot learning 또는 priming (In-context learning)에 사용할 수 있지만, 특히 데이터가 적은 상황에서 분류기에 추가 작업 정보를 제공하기 위한 fine-tuning에도 사용할 수 있음 (PET).
- 그렇다면 자연스럽게 “How Many Data Points is a Prompt Worth? “에 대한 물음을 할 수 있음
2. Related Work
- Prompt는 zero-shot 과 fine-tuning method 모두에서 사용되었음
- Zero-shot은 fine-tuning을 사용하지 않고 prompt에만 의존함 (GPT2)
- Model : Prompt → Answer
- GPT3는 prompt를 이용하는 Priming (ICL)을 사용함
- AR : Prompt + few-shot → Answer
- T5는 prompt based fine-tuning을 사용함
- Encoder : prompt → Decoder : Answer
- 이 논문의 세팅은 T5와 GPT2 세팅 사이에 있는 task-based prompts를 사용하는 PET 세팅과 비슷함
- PET는 성능을 얻기위해 아래와 같은 다양한 테크닉을 사용하지만 이 논문에서는 fine-tuning 내에서 prompt의 기여를 분리하여 분석하는 것임
- Semi-supervision via additional pseudo-labeled data
- Ensembling models trained with several different prompts
- Distilling the ensemble into a linear classifier rather than a language model
3. Comparison: Heads vs Prompts
- 텍스트 분류를 위한 두가지 transfer learning setting
- Head-based: where a generic head layer takes in pretrained representations to predict an output class.
- Prompt-based: where a task-specific pattern string is designed to coax the model into producing a textual output corresponding to a given class.
- PET 표기법을 따르며, Prompt를 pattern과 verbalizer로 구분함
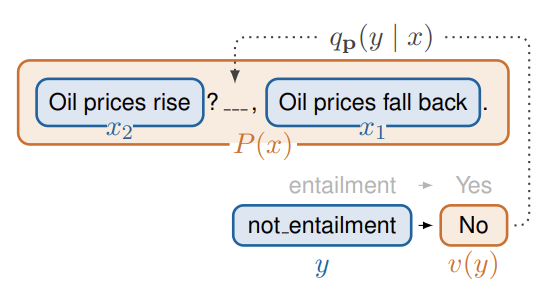
- pattern은 input text를 masked token이 존재하는 cloze task로 변경함
- e.g)

- 각 문장들이 pattern
-
에는 원래 True / False가 들어가지만 verbalizers (yes / no)가 대체함 - v(True) ⇒ yes
- Yes / No - binary question 에 대한 예시
- Pattern : Bold text
- Verbalizer :
token 예측은 클래스를 생성하는 verbalizer에 매핑됨
- pattern은 input text를 masked token이 존재하는 cloze task로 변경함

- 하나의 task에 여러개의 pattern-verbalizer pairs (PVPs) 를 사용할 수 있으며, fine-tuning시의 loss는 정답과 verbalizer의 토큰의 확률분포 사이의 cross entropy.
-
Pattern은 PET 논문에 나오는 것을 그대로 사용
- Choice of prompts : 아래 토글을 클릭하여 볼 수 있음
► Toggle (Click me)


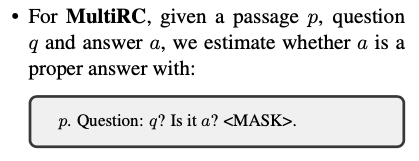


4. Experimental Setting
- RoBERTa-large (335M)
- To train at a low learning rate (10e-5) for a large number of steps (always at least 250, possibly for over 100 epochs)
- SuperGLUE and MNLI
- Entailment : MNLI, RTE, CB
- Multiple choice question answering : BoolQ, MultiRC
- Commonsense reasoning : WSC, COPA, WiC
- ReCoRD (Reading Comprehension with Commonsense Reasoning) 는 사용하지 않음
5. Results
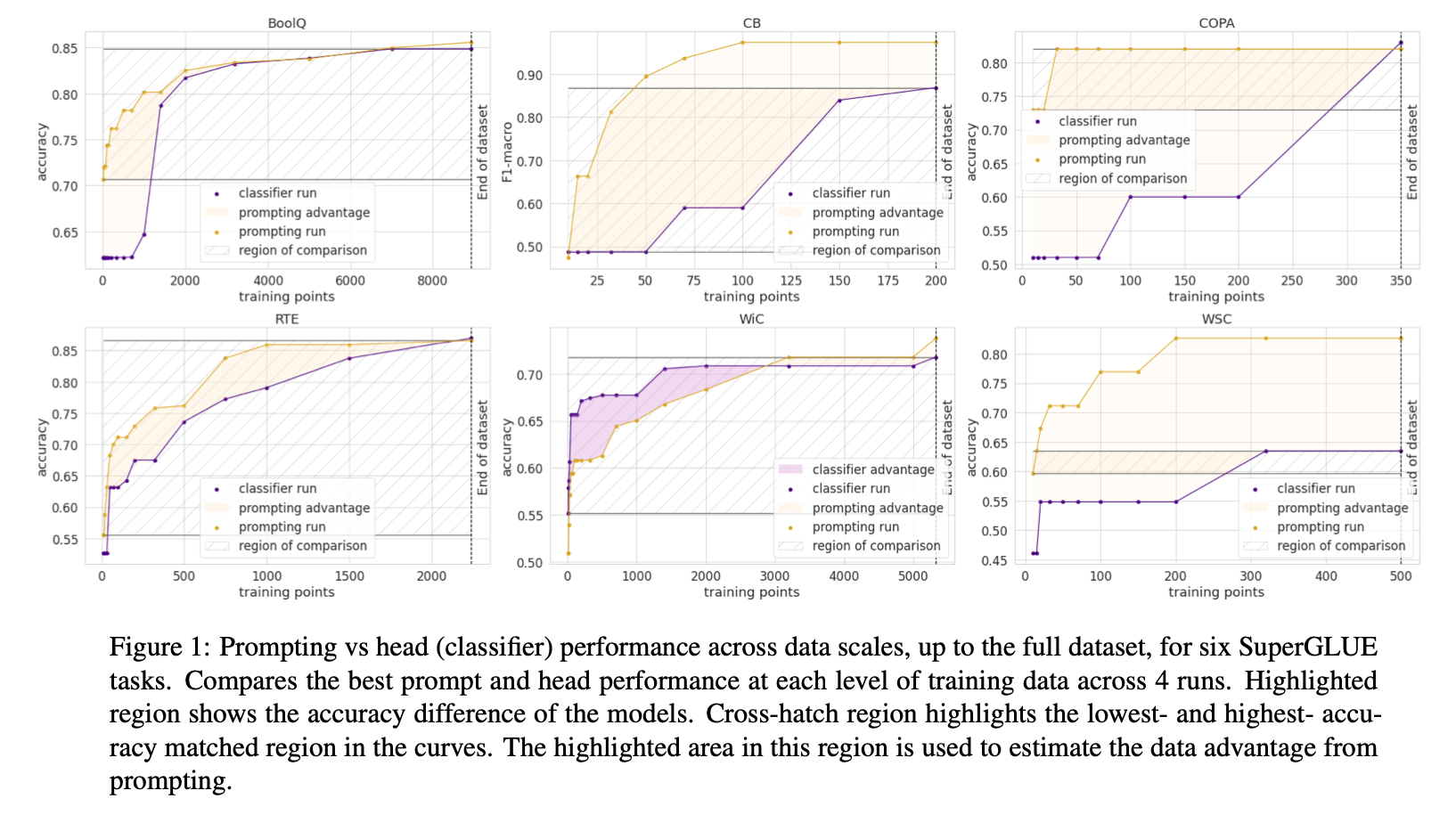
- prompt-based 에서는 가장 잘 작동하는 pattern을 사용함
- 같은 성능을 얻기 위해 사용된 데이터 수를 봄
- WiC를 제외한 결과에 대해서 head-based 보다 prompt-based가 더 좋음
- 같은 성능을 얻기위해 prompt-based가 더 적은 수의 데이터를 사용함
- 데이터 양이 늘어날 수록 두 방법론 모두 성능이 향상되지만 prompt-based가 더 향상이 많음
- 하이라이트 되어 있으면서 cross-hatch region의 넓이를 horizontal line의 높이로 나누어 같은 성능에서 프롬프트가 어느정도의 데이터의 개수를 대체할 수 있는지를 간접적으로 계산함 (대충 평균값)
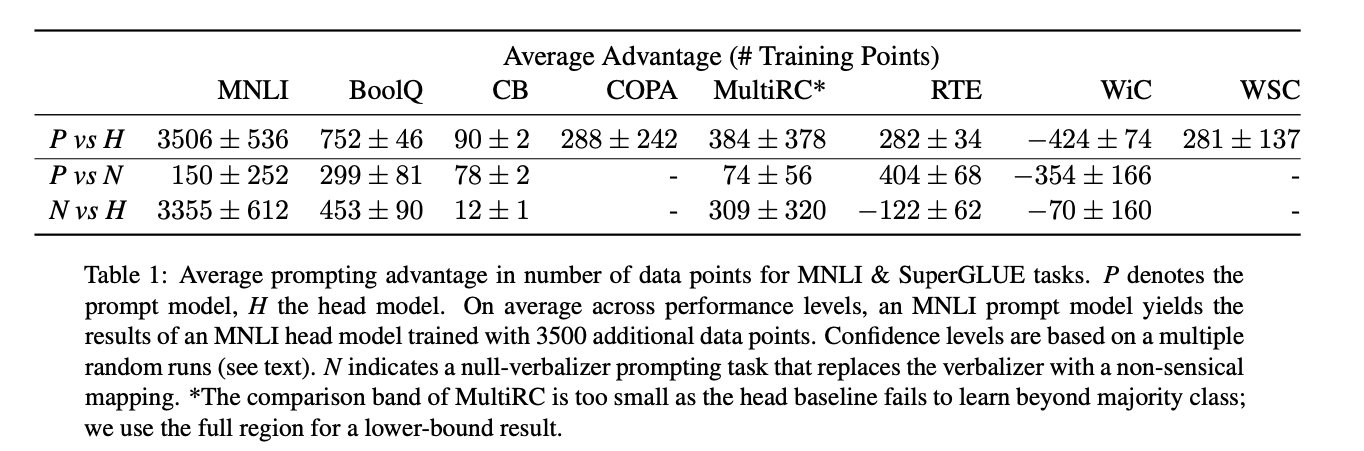
- 거의 모든 작업에 대해 prompt-based 가 데이터 효율성 측면에서 상당한 이점을 제공함.
- head-based 대비 평균적으로 수백 개의 데이터 포인트에 해당하는 이점을 얻음.
6. Analysis
Impact of Pattern vs Verbalizer
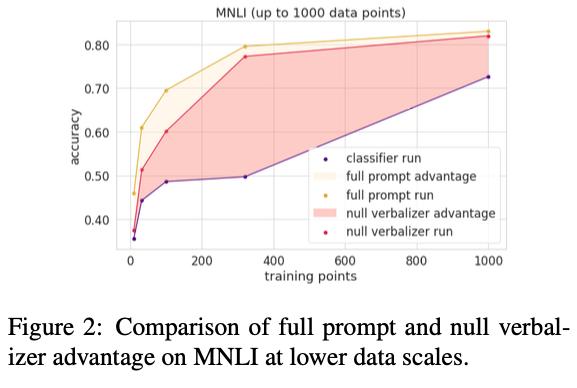
- 직관적으로 Prompt는 훈련 데이터가 거의 없어도 natural language로 task description을 도입을 하여 모델에 도움을 줄 수 있음.
- prompt의 적응적 특성을 이해하기 위해 학습 없이는 의미 정보를 얻을 수 없는 null verbalizer를 도입하여 실험
-
에 한 단어를 입력해야하는 모든 task에 대해 "yes", "no", "maybe", "right", "wrong" 과 같은 verbalizer를 임의의 단어로 대체함 - 그 결과, CB와 같이 데이터가 적을 경우에는 null verbalizer와 full prompt 성능차이가 꽤 존재하지만, 데이터가 많아질수록 모델은 pattern의 inductive bias의 이점을 얻어 verbalizer를 조정하여 성능차이를 완화 시킴
- 이 결과는 prompt가 훈련의 생성 프로세스와 직접적으로 유사하지 않더라도 데이터 효율성을 제공한다는 것을 보여줌.
Impact of Different Prompts
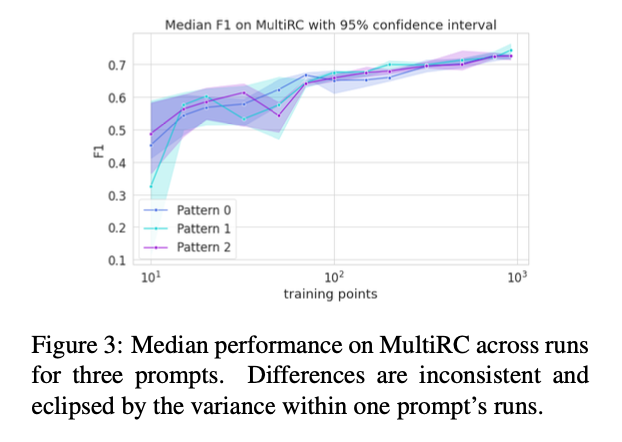
- 어떤 Prompt를 선택함에 따라 성능차이가 날 수 있음
- 하지만, 이 논문에서 사용된 프롬프트의 차이를 분석해 본 결과 거의 모든 실험에서 성능의 신뢰구간이 겹쳤으며, 이는 프롬프트의 선택이 성능 자체에 크게 영향을 미치지 않음을 이야기함
Metric sensitivity
- We treat each metric linearly in calculating advantage; alternatively, we could reparameterize the y axis for each task. This choice does not have a consistent effect for or against prompting. For example, emphasizing gains close to convergence increases prompting advantage on CB and MNLI but decreases it on COPA or BoolQ.
7. Conclusion
We investigate prompting through a systematic study of its data advantage. Across tasks, prompting consistently yields a varying improvement throughout the training process. Analysis shows that prompting is mostly robust to pattern choice, and can even learn without an informative verbalizer. On large datasets, prompting is similarly helpful in terms of data points, although they are less beneficial in performance. In future work, we hope to study the mechanism and training dynamics of the prompting benefits.
8. Impact statement
Significant compute resources were used to run this paper’s experiments. A single experiment (defined as one model run, at one data level, on one task) was quite light-weight, taking usually a little un- der an hour on a single Nvidia V100. However, as we computed a little under two thousand runs, this adds up to about 1800 GPU hours, to which one must add around 400 GPU hours of prototyping and hyper-parameter searching. Those 2200 GPU hours would usually have necessitated the release of about 400kg of CO2, about 40% of a transatlantic flight for a single passenger, in the country where we ran the experiments, although we used a carbon-neutral cloud compute provider. The main benefit of prompting, rather than compute efficiency, is data efficiency. Although we ran all of our experiments on English, we hope that this property will be especially helpful in low-resource language applications. In a sense, a practitioner could then remedy the lack of task-specific data in their language by introducing information through a prompt. However, this comes with the inherent risk of introducing human biases into the model. Prompt completion also suffers from biases already present within the language model (Sheng et al., 2019). This could cause a prompted model to repeat those biases in classification, especially in the few-shot setting where prompting mostly relies on the pretrained model.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA