How Can We Know What Language Models Know?
- 14 minsAuthors : Zhengbao Jiang, Frank F. Xu, Jun Araki, Graham Neubig / CMU, Bosch Research North America
Transactions of the Association for Computational Linguistics 2020
Paper : https://arxiv.org/pdf/1911.12543.pdf
Code : https://github.com/jzbjyb/LPAQA
Summary
- Prompt 생성을 위한 Mining-based Generation, Paraphrasing-based Generation 을 제안하며 앙상블 하는 방법도 제안
- Mining-based와 manual 하게 생성된 prompt를 합쳐서 weighted ensemble 하는 것이 성능이 가장 좋음
- Manual prompts가 구문적으로 더 복잡하거나 Mined prompts 보다 덜 일반적인 구문을 사용하는 경우 Mined prompts가 더 좋음
- 즉, Manual prompts가 항상 optimal은 아니고 weak lower bound 일 수 있음
개인적 견해
- BIG PLM 시대에서 Prompt를 어떤 방식으로 구성할지에 대해 생각할 수 있음
- But, MLM 방식에 대한 연구 결과이며, GPT-3와 같은 AR 모델에 대한 연구가 추가로 필요함
- 결국 학습 셋에 통계적으로 유사한 프롬프트를 구성하고, 앙상블 하는 것이 좋은 건가?
- Manual prompt
- Auto prompt, Prompt programming 등 prompt engineering 분야가 새롭게 떠오르며 빠른 발전을 보이는 중
Abstract
Recent work has presented intriguing results examining the knowledge contained in language models (LM) by having the LM fill in the blanks of prompts such as “Obama is a __ by profession”. These prompts are usually manually created, and quite possibly sub-optimal; another prompt such as “Obama worked as a __” may result in more accurately predicting the correct profession. Because of this, given an inappropriate prompt, we might fail to retrieve facts that the LM does know, and thus any given prompt only provides a lower bound estimate of the knowledge contained in an LM. In this paper, we attempt to more accurately estimate the knowledge contained in LMs by automatically discovering better prompts to use in this querying process. Specifically, we propose mining-based and paraphrasing-based methods to automatically generate high-quality and diverse prompts, as well as ensemble methods to combine answers from different prompts. Extensive experiments on the LAMA benchmark for extracting relational knowledge from LMs demonstrate that our methods can improve accuracy from 31.1% to 39.6%, providing a tighter lower bound on what LMs know. We have released the code and the resulting LM Prompt And Query Archive (LPAQA) at https://github.com/jzbjyb/LPAQA.
1. Introduction
- 최근 Langauge Model (LM)은 텍스트 생성 또는 자연어의 유창성 평가 도구에서 NLU 도구로 전환됨
- Pre-training and Fine-tuning 기법으로 인해 달성
- LM을 통해 객관식문제를 풀거나 주관식에 답을 직접 생성하는 방식으로 사용될 수 있음
- 이러한 패러다임은 사용자가 제공하는 프롬프트에 의존됨
- 이러한 프롬프트는 sub-optimal 일 수 있다.
- 사용자 : “Barack Obama was born in __”
- LM이 학습한 Context : “The birth place of Barack Obama is Honolulu, Hawaii.”
- 이러한 경우 효과적이지 않으며, LM이 가지는 지식 범위의 하한일 수도 있다.
- “How can we tighten this lower bound and get a more accurate estimate of the knowledge contained in state-of-the-art LMs?”
- 다음 방법론을 제안
- Mining-based method
- Paraphrasing-based method
- 앙상블
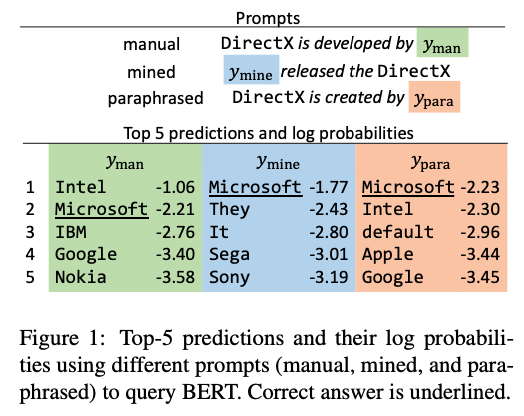
2. Knowledge Retrieval from LMs
- Kwnoledge Retrieval from LMs은 “Barack Obama was born in __” 처럼 자연어 프롬프트를 쿼리로 하여 공백을 찾도록 하는 형태
- Standard declarative knowledge bases 와는 달리 정확성이나 성공을 보장하지 않음
- Factual knowledge is in the form of triples ⟨ x, r, y ⟩.
- x : subject
- y : object
- r : their corrsponding relation
- To query the LM, r is associated with a cloze style prompt \(t_{r}\) consisting of a sequence of tokens, two of which are placeholders for subjects and objects (e.g., “x plays at y position”).
- The existence of the fact in the LM is assessed by replacing x with the surface form of the subject, and letting the model predict the missing object
- (e.g., “LeBron James plays at __ position”)
- 즉, 아래의 형태로 나타낼 수 있음.
- Where V is the vocabulary, and \(P_{\text{LM}}(y'\vert x,t_{r})\) is the LM probability of predicting \(y'\) in the blank conditioned on the other tokens.
- 좋은 프롬프트는 LM이 가능한 자주 ground-truth objects를 예측하도록 만드는 프롬프트임.
3. Prompt Generation
3. 1. Mining-based Generation
- subject x 와 object y 의 주변 단어들이 종종 relation r 을 설명한다는 관찰 바탕인 템플릿 기반 관계 추출 방법에서 영감을 얻음.
- 이러한 직관을 바탕으로 두가지 방법 제안
- 프롬프트 추출을 위한 문장들은 위키피디아를 이용함
Middle-word Prompts
- Subject와 object 사이에 있는 단어가 관계를 나타내는 경우가 많다는 관찰에 따라 해당 단어들을 프롬프트로 직접 이용
- e.g., “Barack Obama was born in Hawaii” → “x was born in y”
Dependency-based Prompts
- 중간에 단어가 나타나지 않는 템플릿의 경우 문장의 구문 분석을 기반으로 한 템플릿이 관계 추출에 더 효과적 일 수 있음
- Dependency parser를 통해 구문 분석 후 subject와 object 사이의 가장 짧은 dependency path를 찾은 다음 dependency path의 맨 왼쪽 단어에서 맨 오른쪽 단어에 이르는 구(phrase)를 프롬프트로 사용함
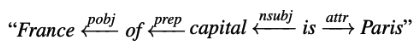
- where the leftmost and rightmost words are “capital” and “Paris”.
- e.g., “The capital of France is Paris” → “capital of x is y”
두 기법은 수동으로 생성 된 프롬프트에 의존하지 않으므로 subject-object paris를 얻을 수 있는 모든 관계에 대해 유연하게 적용이 가능하며 다양한 프롬프트가 만들어짐
그러나 이런 방식으로 얻은 프롬프트는 관계를 잘 나타내지 않을 수 있기에 프롬프트가 오히려 noise가 될 수 있음
3. 2. Paraphrasing-based Generation
- Original prompt를 의미상 유사하거나 동일한 표현으로 패러프레이징 하여 어휘 다양성을 증가시키는 방법
- e.g., “x shares a border with y” → “x has a common border with y” / “x adjoins y”
- Back-translation을 이용하여 패러프레이징 함
- Round-trip probability를 바탕으로 top T prompts를 사용함
- Round-trip probability : \(P_{\text{forward}}(\bar{t}\vert \hat{t})\cdot P_{\text{backward}}(t\vert \bar{t})\), where \(\hat{t}\) is the initial prompt, \(\bar{t}\) is the translated prompt in the other language, and \(t\) is the final prompt.
4. Prompt Selection and Ensembling
4. 1. Top-1 Prompt Selection
- 각 프롬프트에 대해 다음을 사용하여 학습데이터에 대해 ground-truth objects에 대한 정확도를 구할 수 있음.
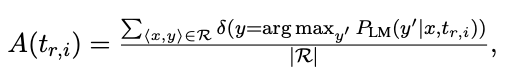
- Where R is a set of subject-object paris with relation r, and \(\delta(\cdot)\) is Kronecker’s delta function, returning 1 if the internal condition is true and 0 otherwise.
- 정확도가 가장 높은 프롬프트를 사용
4. 2. Rank-based Ensemble
- 학습데이터에 대한 정확도를 기준으로 모든 프롬프트에 순위를 매기고 상위 K 개의 프롬프트의 average log probabilities를 구함
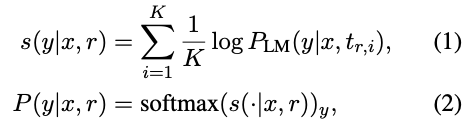
4. 3. Optimized Ensemble
- Rank-based 와 비슷하지만 프롬프트 별 가중치를 주고, 가중치는 아래와 같은 식으로 최적화 함 (식 1을 변형)
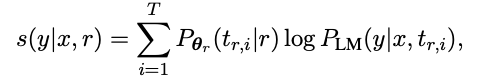
- where \(P_{\theta_{r}}(t_{r,i}\vert r) = \text{softmax}(\theta_{r})\) is a distribution over prompts parameterized by \(\theta_{r}\), a T-sized real-value vector.
- The parameter \(\theta_{r}\) is optimized to maximize the probability of the gold-standard objects \(P(y\vert x,r)\) over training data.
5. Main Experiments
5. 1. Experimental Settings
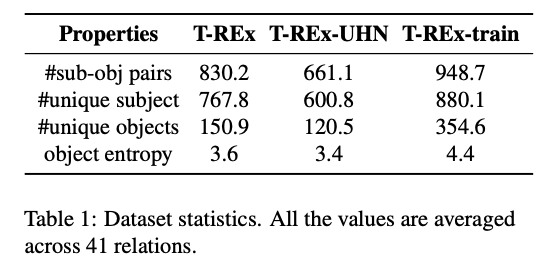
Dataset
- T-REx subset of the LAMA benchmark
- LM 고유의 “factual and commonsense knowledge” 를 측정
- Knowledge base triple (S, R, O) 이 주어졌을때 Cloze-style query로 부터 object가 도출됨
- e.g., (Jean Marais, native-language, French) → “The native language of Jean Marais is [MASK].”
- Trainset (T-REx-train) : 프롬프트를 구성하기 위해 Wikidata 에서 T-REx와 겹치지 않도록 제작
Models
- BERT-base
- BERT-large
- ERNIE
- Know-Bert
Evaluation Metrics
- micro-averaged accuracy : calculating the accuracy of all subject-object paris for relation r:
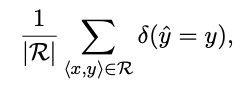
- 일부 관계의 object distribution이 왜곡되어 있음을 발견하고 macro-averaged accuracy를 함께 리포트함
- macro-averaged accuracy : unique object의 정확도를 개별적으로 계산 후 이것을 함께 평균하여 accuracy를 구함
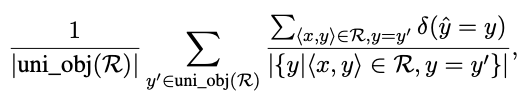
- where uni_obj(R) returns a set of unique objects from realtion r.
Method
- Majority : 각 relation에서의 가장 일반적인 object를 선택할 경우
- Man : manually designed prompts
- Mine : Mining-based Generation with wikipeida
- Mine + Man : Mining-base + manual
- Mine + Para : Mining-base + Paraphrasing-base
-
Man + Para : Manual + Paraphrasing-base
- TopK : highest-ranked prompt
- Opti : the weights after optimization
- Oracle : Upper bound (생성된 프롬프트 중 어느 하나라도 맞춘 경우)
Implementation Details
- T = 40 most frequent prompts either generated through mining or paraphrasing
- number of candidates in back-translation is set to B = 7
- Remove prompt only containing stop-words/punctuation or longer than 10 words
5. 2. Evaluation Results
Single Prompt Experiments
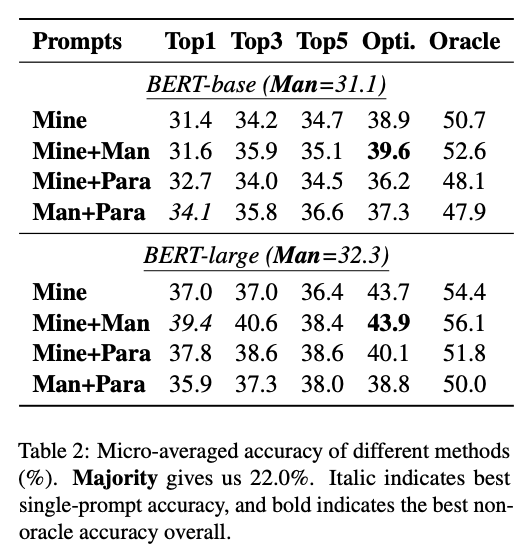
- Top1의 경우 BERT-base 에서 31.1 (Man) → 34.1 (Man+Para) / BERT-large 에서 32.3 (Man) → 39.4 (Mine+Man)
- 수동으로 생성한 프롬프트는 weak lower bound
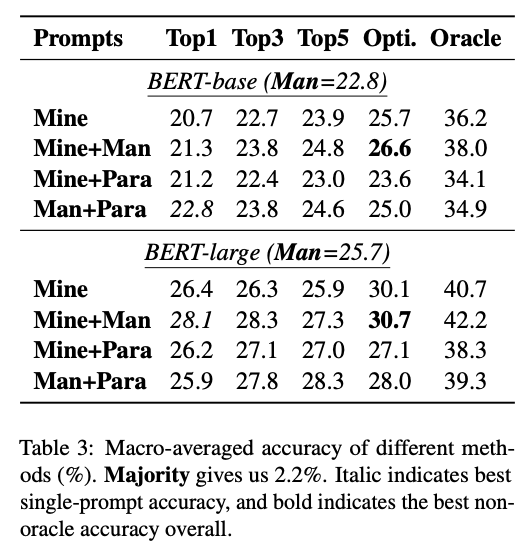

- Manual prompts가 구문적으로 더 복잡하거나 Mined prompts 보다 덜 일반적인 구문을 사용하는 경우 Gain이 크다
Prompt Ensembling
- 대체적으로 Top1 보단 Top3, Top5가 더 좋으며, Opti의 경우가 제일 좋음
- Opti 방법이 서로 다른 프롬프트를 효과적으로 결합하는 weight를 찾을 수 있음을 보여줌

- 가중치는 특정 프롬프트에 집중되는 경향이 있고 다른 프롬프트들은 보완 역할을 함
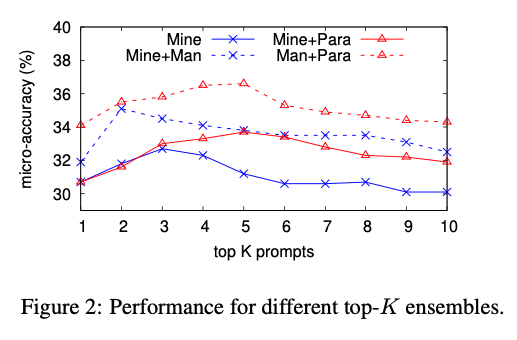
- Mine의 경우 top-2 또는 top-3이 최상의 결과를 제공
- Para의 경우 top-5 가 최고
- 많은 프롬프트를 앙상블 한다고 성능이 향상되는 것은 아님
Mining vs. Paraphrasing
- 순위 기반 앙상블의 경우 패러프레이징으로 생성된 프롬프트가 일반적으로 마이닝 된 프롬프트보다 더 나은 성능을 보여줌
- 최적화 기반 앙상블 (Opti)의 경우 마이닝 된 프롬프트가 더 잘 수행됨 (패러프레이징 보다 더 많은 variation)

- 한 단어 를 변경하면 정확도가 크게 향상 될 수 있음
- 이는 large-scale LM이 작은 변화에 여전히 취약함을 보임
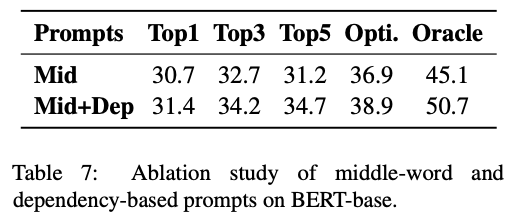
Middle-word vs. Dependency-based
Performance of Different LMs
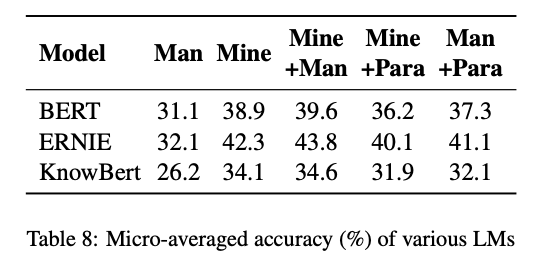
- ERNIE / KnowBert : 엔티티 임베딩을 명시적으로 통합한 모델
- ERNIE > BERT > KnowBert
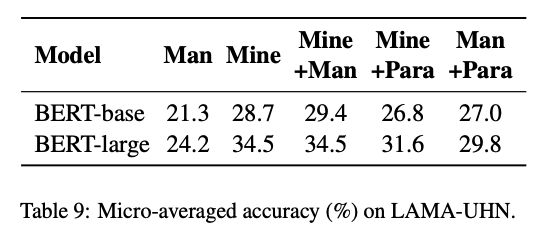
LAMA-UHN Evaluation
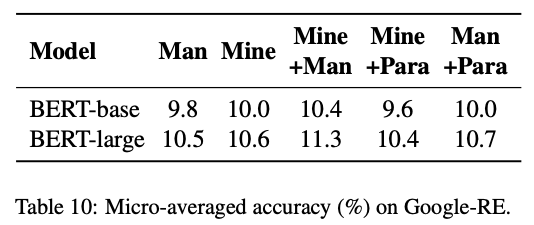
Performance on Google-RE
5. 3. Analysis
Prediction Consistency by Prompt
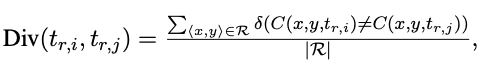
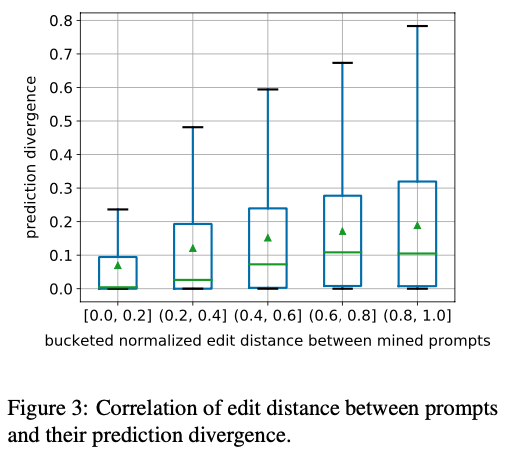
- Eidit distance가 커지면 divergence가 증가하여 매우 다른 프롬프트가 다른 예측 결과를 유발하는 경향이 있음
- 피어슨 상관 계수는 0.25로 weak correlation가 있음
POS-based Analysis

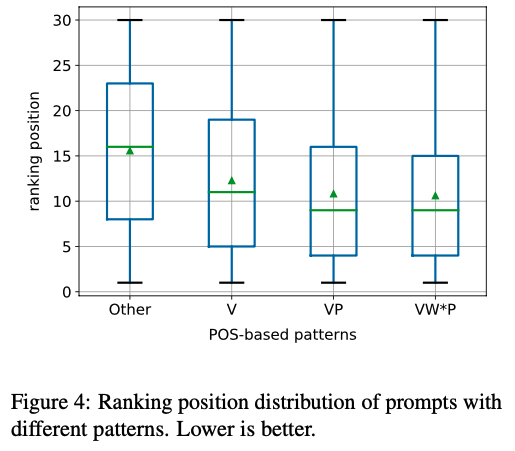
- Table 11에 있는 패턴이 Other 보다 더 나으며, 좋은 프롬프트가 이러한 패턴을 따라야 함
- 가장 성능이 좋은 프롬프트의 POS 일부
- “x VBD VBN IN y” (e.g., “x was born in y”)
- “x VBZ DT NN IN y” (e.g., “x is the capital of y”).
Cross-model Consistency
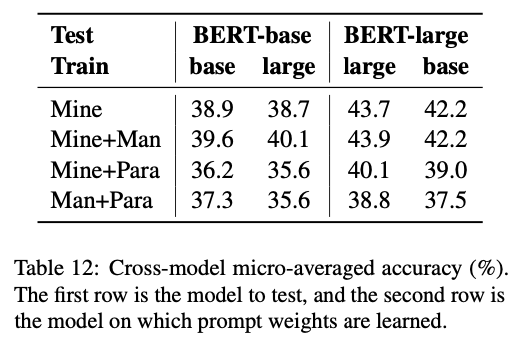
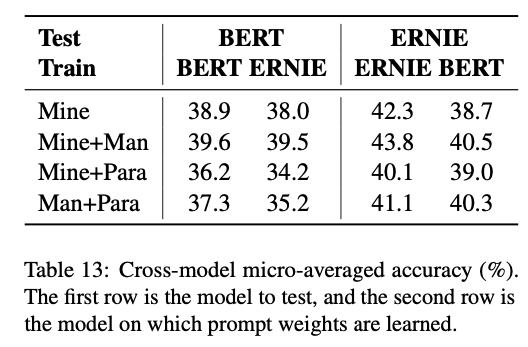
- 프롬프트를 학습하는 모델과 테스트 하는 모델을 다르게 하였을때 대부분 성능이 하락됨
- 여기에서도 Mine + Man 이 가장 좋은 성능을 보임
- BERT-base → BERT-large 보다 BERT-base → ERNIE 가 성능 하락이 더 큼
- 이는 같은 프롬프트를 사용할때 동일한 아키텍쳐를 사용하는것이 좋음을 보여줌
Linear vs. Log-linear Combination
- 앙상블 시 기존의 식 (Log-linear) 를 Linear로 변경할 수 있음 (1) → (4)
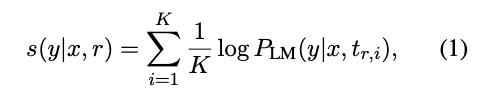
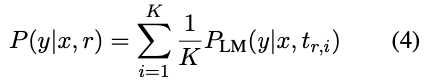
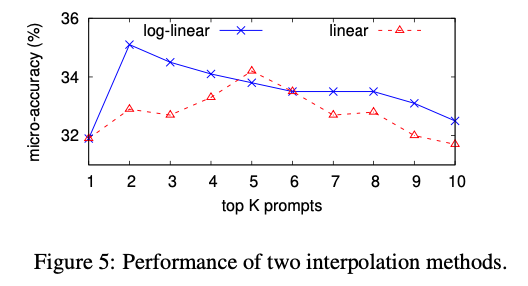
- We assume that log-linear combination outperforms linear combination because log probabilities make it possible to penalize objects that are very unlikely given any certain prompt.
6. Omitted Design Elements
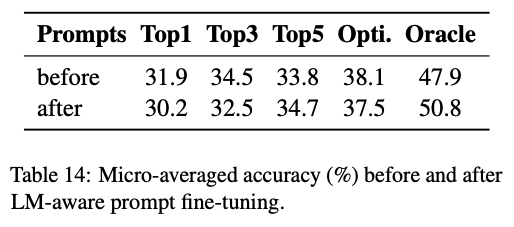
6. 1. LM-aware Prompt Generation
- 프롬프트에 대해 gorund-truth objects를 생성할 확률을 최대화하는 최적화 문제로 풀어봄
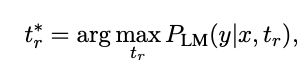
- 생성되는 프롬프트가 불안정하여 성능이 오히려 떨어짐
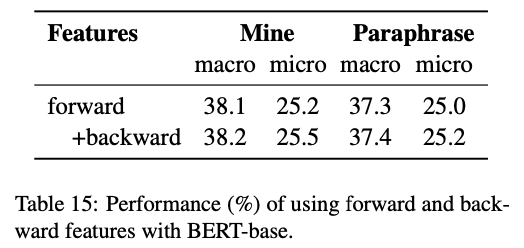
6. 2. Forward and Backward Probabilities
7. Related Work
Much work has focused on understanding the internal representations in neural NLP models (Belinkov and Glass, 2019), either by using extrinsic probing tasks to examine whether certain linguistic properties can be predicted from those representations (Shi et al., 2016; Linzen et al., 2016; Belinkov et al., 2017), or by ablations to the models to investigate how behavior varies (Li et al., 2016b; Smith et al., 2017). For contextualized representations in particular, a broad suite of NLP tasks are used to analyze both syntactic and semantic properties, providing evidence that contextualized representations encode linguistic knowledge in different layers (Hewitt and Manning, 2019; Tenney et al., 2019a,b; Jawahar et al., 2019; Goldberg, 2019). Different from analyses probing the representations themselves, our work follows Petroni et al. (2019); Pörner et al. (2019) in probing for factual knowledge. They use manually defined prompts, which may be under-estimating the true performance obtainable by LMs. Concurrently to this work, Bouraoui et al. (2020) made a similar observation that using different prompts can help better extract relational knowledge from LMs, but they use models explicitly trained for relation extraction whereas our methods examine the knowledge included in LMs without any additional training. Orthogonally, some previous works integrate external knowledge bases so that the language generation process is explicitly conditioned on symbolic knowledge (Ahn et al., 2016; Yang et al., 2017; IV et al., 2019; Hayashi et al., 2020). Similar extensions have been applied to pre-trained LMs like BERT, where contextualized representations are enhanced with entity embeddings (Zhang et al., 2019; Peters et al., 2019; Pörner et al., 2019). In contrast, we focus on better knowledge retrieval through prompts from LMs as-is, without modifying them.
8. Conclusion
In this paper, we examined the importance of the prompts used in retrieving factual knowledge from language models. We propose mining-based and paraphrasing-based methods to systematically generate diverse prompts to query specific pieces of relational knowledge. Those prompts, when combined together, improve factual knowledge retrieval accuracy by 8%, outperforming manually designed prompts by a large margin. Our analysis indicates that LMs are indeed more knowledgeable than initially indicated by previous results, but they are also quite sensitive to how we query them. This in- dicates potential future directions such as (1) more robust LMs that can be queried in different ways but still return similar results, (2) methods to incorporate factual knowledge in LMs, and (3) further improvements in optimizing methods to query LMs for knowledge. Finally, we have released all our learned prompts to the community as the LM Prompt and Query Archive (LPAQA), available at: https://github.com/jzbjyb/LPAQA.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA