EDA : Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
- 7 minsAuthors : Jason Wei, Kai Zou
Protago Labs Research / Dartmouth College / Georgetown University
EMNLP 2019
Paper : https://arxiv.org/pdf/1901.11196.pdf
Code : https://github.com/jasonwei20/eda_nlp
Summary
Synonym Replacement, Random Insertion / Random Swap / Random Deletion 방식을 사용하여 Data Augmentation 을 한다.
기존 방법들과 달리 외부 데이터나 모델 훈련 없이 성능을 증가 시킬 수 있었다.
개인적 견해
- Parameter search 및 ablation study 까지 진행한 좋은 연구라고 생각한다.
- 하지만 이게 정말 reproduce이 될지, 다양한 데이터셋에서 robust 한지에 대한 의문이 남아 있다.
- 또한 다른 paper들과 비교할 수 없어서 아쉬운 점이 크다 → data augmentation에 대한 bench mark dataset / model이 필요 !!
- ELMo / BERT와 같은 pre-trained model에서는 효과가 미미한 점도 아쉽다.
- 트랜트를 빠르게 따라가면 간단한 아이디어도 좋은 결과를 얻을 수 있다.
- 아무리 생각해도 Computer Vision 쪽에서 Natural Language Processing으로 넘어오는 기술들이 많은 것 같다.
Abstract
We present EDA: easy data augmentation techniques for boosting performance on text classification tasks. EDA consists of four simple but powerful operations: synonym replacement, random insertion, random swap, and random deletion. On five text classification tasks, we show that EDA improves performance for both convolutional and recurrent neural networks. EDA demonstrates particularly strong results for smaller datasets; on average, across five datasets, training with EDA while using only 50% of the available training set achieved the same accuracy as normal training with all available data. We also performed extensive ablation studies and suggest parameters for practical use.
1. Introduction
- Natural Language Processing 분야에서 Machine Learning이 이용되면서 높은 성능을 달성 할 수 있었다.
- 하지만 성능은 데이터의 질과 양에 의존적이지만, 데이터를 얻는 것은 쉽지 않다.
- Automatic data augmentation은 Computer Vision 분야에서는 이미 널리 사용되며, 적은 양의 데이터로도 robust 한 모델을 만들 수 있게 도움을 준다.
- 그러나 NLP에서는 Language transformation을 일반화 시키기 어렵기 때문에 연구가 되지 않았다.
- Back translation이나 contextual data augmentation 방법론들이 존재하였지만, 이러한 방법들은 상대적으로 학습시킬때 비용이 크므로 잘 사용되지 않는다.
- 저자들은 Easy Data Augmetation (EDA) 라고 명하는 NLP를 위한 간단하면서도 universal한 data augmentation technique 을 제안한다.
2. EDA
- Training set에서 데이터가 주어졌을때, 아래와 같은 방법 중 랜덤으로 선택하여 적용함
2.1 Synonym Replacement (SR)
: 주어진 문장에서 stop words가 아닌 \(n\)개의 단어를 선택하여 synonyms 중 랜덤으로 치환한다.
All synonyms for synonym replacements and random insertions were generated using WordNet (Miller, 1995).
2.2 Random Insertion (RI)
: 문장에서 stop word가 아닌 단어의 동의어를 찾고 해당 동의어를 문장의 임의의 위치에 삽입하는 것을 \(n\)번 반복 한다.
2.3 Random Swap (RS)
: 랜덤으로 2개의 단어를 선택하여 위치를 바꾼다. \(n\)번 반복한다.
2.4 Random Deletion (RD)
: 문장 내에서 각각의 단어에 대해 \(p\) 확률로 지운다.
- 긴 문장은 짧은 문장보다 단어가 많기에 원래의 레이블을 유지하면서 더 많은 노이즈를 추가할 수 있다.
- 따라서 \(n=al\) 식을 이용하여 \(n\)을 정해준다.
- 이때 \(a\)는 문장에서 변경될 (위 방법이 적용될) 단어의 비율이며, RD에서 사용되는 \(p\)와 동일하게 사용한다. \(l\)은 문장의 길이이다.
- 또한, 각각의 original 문장에 대해 \(n_{aug}\) 만큼 생성한다.
- Synonym replacement 기법은 이전에 존재하였지만, 나머지는 존재하지 않았다.
- 생성된 문장은 아래와 같다.
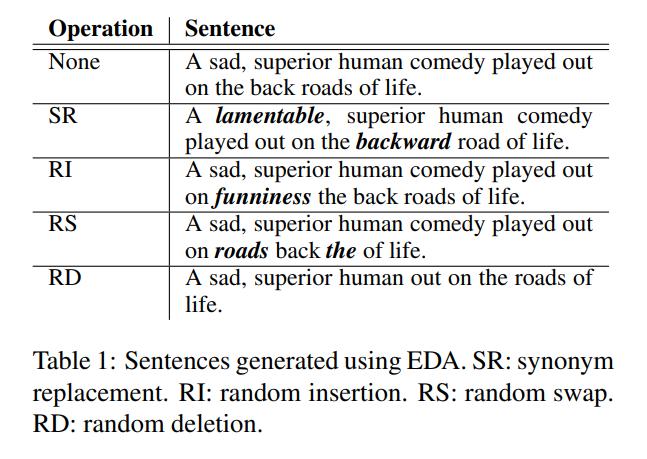
3. Experimental Setup
- 5개의 텍스트 분류 벤치마크 데이터 셋에 대해서 두개의 넨트워크 구조로 EDA를 평가하였다.
3.1 Benchmark Datasets
- SST-2 : Stanford Sentiment Treebank
- CR : customer reviews
- SUBJ : subjectivity/objectivity dataset
- TREC : question type dataset
- PC : Pro-Con dataset
각 데이터 셋의 통계량은 다음과 같다.
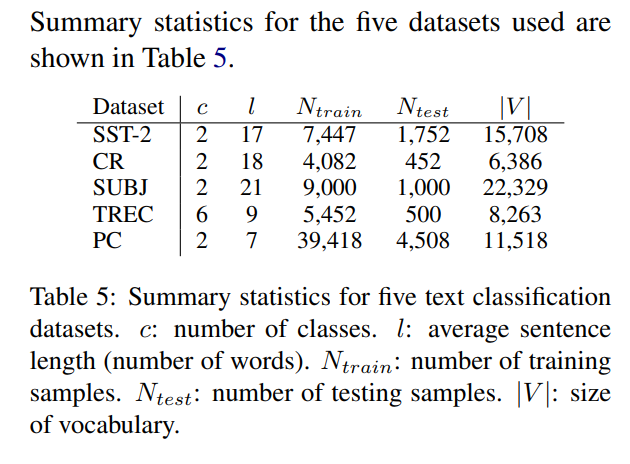
EDA는 dataset이 적을 때 성능을 향상시켜 줄 것이라는 가정을 하고 있기 때문에 datasets의 랜덤으로 줄여서 테스트를 한다. 총 4개의 subset 및 full set으로 평가한다.
Training set : \(N_{train}\) = {500, 2,000, 5,000, all available data}
3.2 Text Classification Models
-
Recurrent Neural Networks (RNNs) : LSTM-RNN
The architecture used in this paper is as follows: input layer, bi-directional hidden layer with 64 LSTM cells, dropout layer with p=0.5, bi-directional layer of 32 LSTM cells, dropout layer with p=0.5, dense layer of 20 hidden units with ReLU activation, softmax output layer. We initialize this network with random normal weights and train against the categorical crossentropy loss function with the adam optimizer. We use early stopping with a patience of 3 epochs.
-
Convolutional Neural Networks (CNNs) : Yoon Kim’s CNNs
We use the following architecture: input layer, 1D convolutional layer of 128 filters of size 5, global 1D max pool layer, dense layer of 20 hidden units with ReLU activation function, softmax output layer. We initialize this network with random normal weights and train against the categorical cross-entropy loss function with the adam optimizer. We use early stopping with a patience of 3 epochs.
- We use 300 dimensional word embeddings trained using GloVe (Pennington et al., 2014).
4. Results
4.1 EDA Makes Gains
- 아래의 표 하나로 설명이 가능하다.
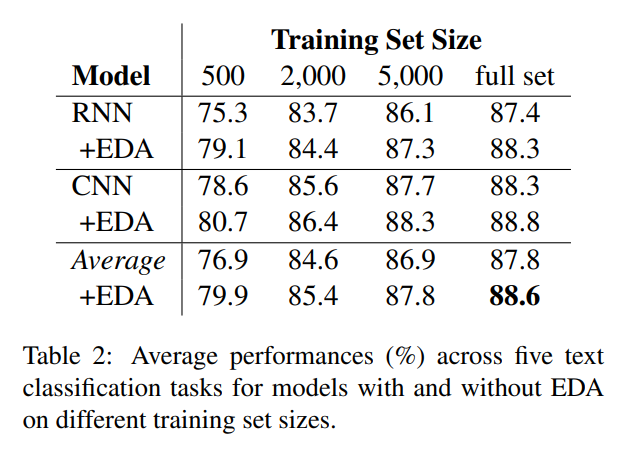
4.2 Training Set Sizing
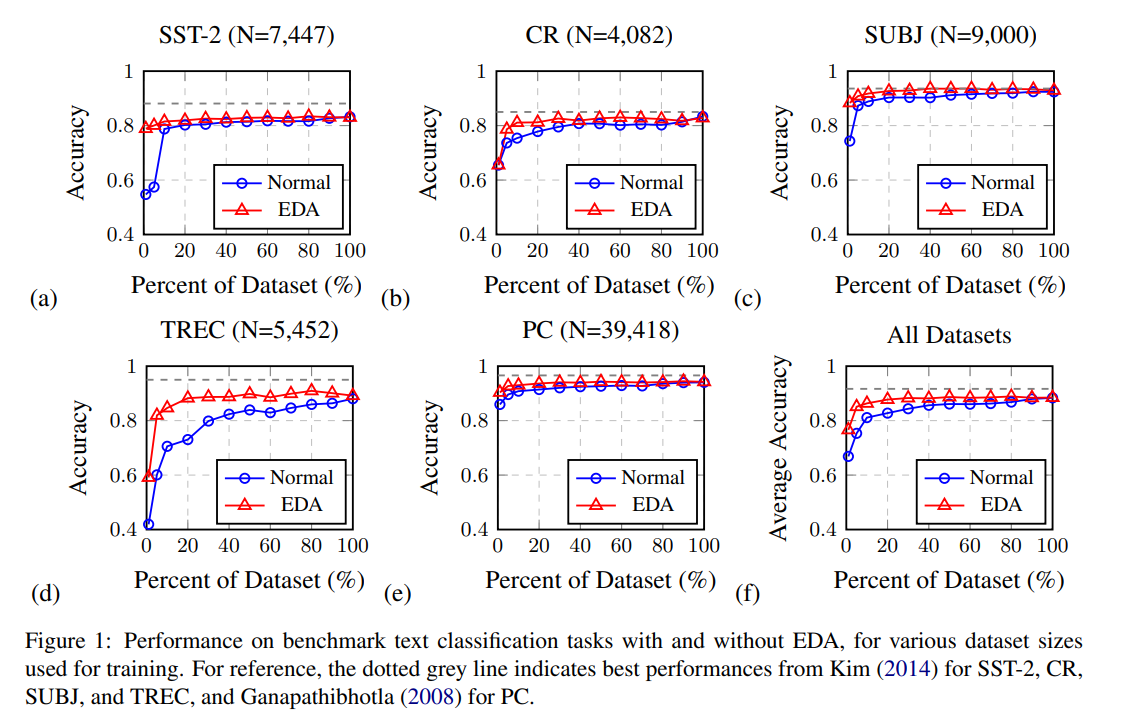
- 작은 dataset에 대해서 overfitting이 더 심한 경향이 있다.
- 작은 dataset에서 EDA는 더 효과적이다.
- 저자들은 EDA를 적용한것과 하지 않은 것으로 {1, 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100} % 의 fractions 들로 테스트 했다.
- wo/EDA 에서는 전체 데이터를 사용했을 때 88.3% 최고 성능이 나왔지만 w/EDA 에서는 50%의 데이터만으로도 88.6%의 성능이 나왔다.
- 데이터의 수가 적을 수록 성능 개선의 폭이 크다.
- 실험 결과는 아래와 같다.
4.3 Does EDA conserve true labels?
- EDA 적용과정에서 문장이 크게 변화하는 경우 원래의 레이블은 유효하지 않을 수 있다.
- 저자들은 이러한 문제점에 대해 분석하기 위해 시각화를 하였다.
- EDA 없이 PC 데이터에 대해 RNN을 트레이닝 한 후 last dense layer의 output에 대해서 t-SNE를 적용하여 시각화 하였다.
- 그 결과 대부분의 생성된 문장들이 원래의 문장들과 비슷한 위치에 존재하며 문장의 레이블을 보존하고 있었다.
- 시각화 결과는 아래와 같다.

4.4 Ablation Study: EDA Decomposed
- EDA에서 각각의 방법들의 효과를 알아보기 위해 ablation study를 진행했다.
- SR의 경우 기존에 연구가 되었지만, 나머지는 연구가 되지 않았기에 해볼 필요가 있다.
- 개별적으로 해당 방법론들을 적용해본다.
- 파라미터 \(a\)의 경우 {0.05, 0.1, 0.2, 0.3, 0.4, 0.5} 로 적용시킨다.
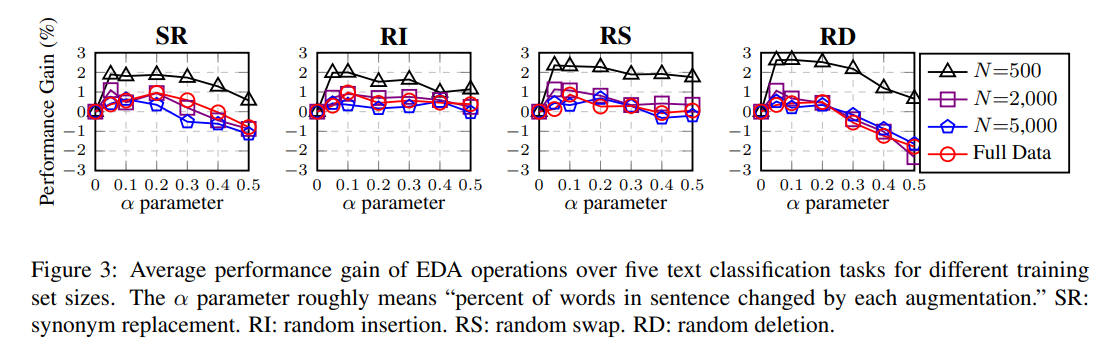
- 실험 결과 네가지 방법 모두 성능 향상에 도움을 준다.
- SR의 경우 \(a\)가 낮을때 좋으며, 높으면 성능이 감소 될 수 있다.
- RI는 \(a\)에 대해서 안정적으로 성능 향상을 얻을 수 있다.
- RS는 0.2 이하일때 좋으며 0.3 이상부터는 떨어지기 시작한다.
- RD는 낮은 \(a\)에서 가장 높은 성능향상을 얻지만 \(a\)가 높아질수록 성능 하락도 크다.
- \(a\) = 0.1 이 sweet spot 이다.
4.5 How much augmentation?
- 개인적으로 중요하다고 생각하는 문장 별 생성할 갯수인 \(a_{aug}\)에 대한 실험이다.
- \(a_{aug}\) = {1, 2, 4, 8, 16, 32} 에 대해서 실험을 해본 결과 적은 데이터셋 일수록 많이 생성하는 것이 좋으며, 적당한 데이터 셋은 이미 일반화가 되어있기에 많이 생성할 필요가 없다.
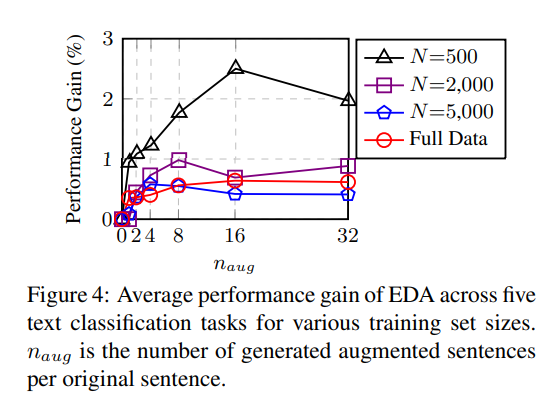
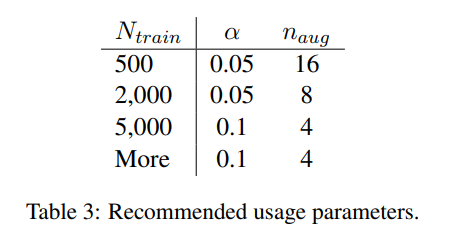
5. Comparsion with Related Work
- Back translation method
- Translation method
- Noising method
- Heuristic method
- Synonym Replacement method
- K-nearest neighbors method
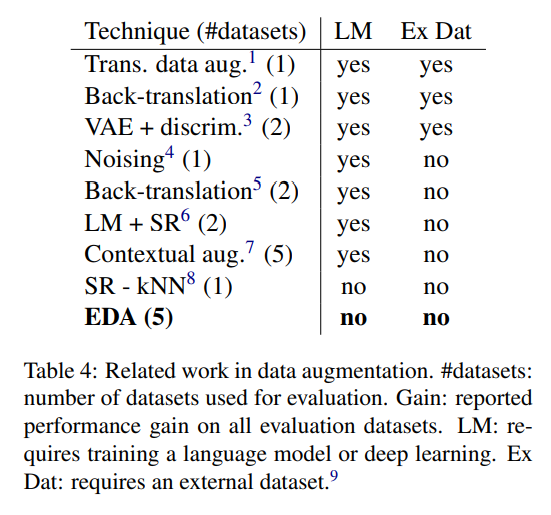
- 제안한 방법이 외부 데이터나 모델 학습이 필요없으면서도 성능 향상을 기대할 수 있기에 좋은 방법이라고 주장
6. Discussion and Limitations
- 데이터가 충분하면 성능 향상이 미미하다.
- pre-trained model에 대해서는 성능향상이 없을 수 있다.
- 다른 모델과 다른 데이터셋에 대해서는 자명하지 않다.
7. Conclusion
We have shown that simple data augmentation operations can boost performance on text classification tasks. Although improvement is at times marginal, EDA substantially boosts performance and reduces overfitting when training on smaller datasets. Continued work on this topic could explore the theoretical underpinning of the EDA operations. We hope that EDA’s simplicity makes a compelling case for further thought.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA