Do Not Have Enough Data? Deep Learning to the Rescue!
- 8 minsAuthors : Ateret Anaby-Tavor, Boaz Carmeli, Esther Goldbraich, Amir Kantor, George Kour, Segev Shlomov, Naama Tepper, Naama Zwerdling IBM Research AI, University of Haifa, Israel, Technion - Israel Institute of Technology
Paper : https://aaai.org/Papers/AAAI/2020GB/AAAI-AnabyA.4027.pdf
Code : None
AAAI 2020 Poster session
Summary
GPT-2 를 이용하여 데이터셋을 생성 한 후, 원래 데이터로 학습 된 classifier를 통해 생성된 데이터를 필터링 하여 남은 것들을 원래 데이터에 추가하는 방식으로 Data Augmentation.
Detail 및 Code가 존재하지 않아 실험에 대한 방법이 궁금한 점이 존재
- # of data augmentation
- Double voting / Semi-supervised approach 등등 설명이 불친절
- 이해가 안되는 부분 존재
Abstract
Based on recent advances in natural language modeling and those in text generation capabilities, we propose a novel data augmentation method for text classification tasks. We use a powerful pre-trained neural network model to artificially synthesize new labeled data for supervised learning. We mainly focus on cases with scarce labeled data. Our method, referred to as language-model-based data augmentation (LAMBADA), involves fine-tuning a state-of-the-art language generator to a specific task through an initial training phase on the existing (usually small) labeled data. **Using the fine-tuned model and given a class label, new sentences for the class are generated. Our process then filters these new sentences by using a classifier trained on the original data. In a series of experiments, we show that LAMBADA improves classifiers’ performance on a variety of datasets. Moreover, LAMBADA significantly improves upon the state-of-the-art techniques for data augmentation, specifically those applicable to text classification tasks with little data.
1. Introduction
- Data augmentation은 데이터가 부족할 때 데이터를 늘리기 위해 방법
- 기존에 존재하는 데이터를 바탕으로 새로운 데이터를 만들어서 모델의 성능을 향상시키는 것
- Cropping, padding, flipping 등 과 같은 다양한 transformation으로 쉽게 augmentation을 할 수 있는 이미지나 Speech recogition 도메인과 달리 텍스트 이러한 방법을 적용하기 어려움
- 그렇기 때문에 특정 단어를 동의어로 교체 또는 삭제, 그리고 임의로 바꾸는 방법들이 사용됨
- 본 논문에서는 text classification task를 위한 language-model-based data augmentation (LAMBADA) 를 소개함.
- Pre-trained GPT-2를 이용하여 specific task dataset에 대하여 fine-tuning을 한 후 새로운 labeled sentence를 생성 함.
- 여기서 GPT-2는 충분히 좋은 퀄리티의 텍스트를 생성한다고 가정을 바탕으로 함
- 이와 별개로 기존 dataset을 바탕으로 classifier를 training 하여 생성된 데이터셋을 이 classifier를 통하여 필터링 함.
- 이렇게 필터링 된 data들은 퀄리티가 보장된다고 가정하며, 새로운 학습 데이터로 사용함.
- 본 논문의 contribution은 다음과 같음
- Data augmentation을 통한 Classifier의 성능 향상
- Data가 적은 상황에서 다른 Data augmentation 기법의 성능을 뛰어넘음
- Unlabeled data가 존재하지 않는 상황에서 semi-supervised techniques을 대체할 수 있음
2. Related Work
- 지금까지 대부분의 textual data augmentation 기법들은 주어진 데이터의 일부(local)를 바꾸는 기법을 사용함 (단어 / 단어들을 동의어로 치환하는 방법).
- 최근 Easy data augmentation (EDA) 에서는 random swap도 사용함.
- 그 외에도 contextual data augmentation 사용함.
- 하지만 이러한 방법은 원래의 데이터와 거의 비슷하므로 코퍼스 수준에서는 변동성이 낮음.
- 다른 방식으로는 variational autoencoder, round-trip translation, paraphrasing, generative adversarial networks 등을 사용함
- 우리는 문장 생성을 잘하는 GPT-2를 이용하여 Data augmentation을 함
3. Problem Definition
Text classification problem에 대한 definition.
자세한 내용은 생략
Text classification is an instance of the supervised learning problem over textual data. …

4. LAMBADA Method
LAMBADA for its use of Language Model Based Data Augmentation, this method adds more synthesized, weakly-labeled data samples to a given dataset.
LAMBADA는 2개의 key ingredients를 갖음
- Labeled data를 생성하는 model의 fine-tuning (step 2)
- 좋은 quality의 문장만 남겨두는 data filtering (step 4)

Input
- Training dataset \(D_{train}\) : containing a set of sentences, each labeled with a class
- Classification Algorithm A : training algorithm for classifier (Arbirary)
- Language model G : GPT-2
- Number to synthesize per class \(N_1\), … , \(N_q\)
4.1 LAMBADA Algorithm
- Step 1: Train baseline classifier
- \(D_{train}\)을 이용하여 Baseline classifier h = A(\(D_{train}\))을 학습함.
- Step 4에서 filter로 사용됨.
- Step 2: Fine-tune language model
-
\(D_{train}\)을 이용하여 language model G를 fine-tune 하여 \(G_{tuned}\)를 얻음.

-
SEP token은 class label과 sentence 구분, EOS token은 문장 끝 표시.
-
- Step 3: Synthesize labeled data
- G_tuned를 이용하여 new labeled sentences를 생성함.
- 처음 Condition으로 “y SEP“을 입력하고 EOS 가 나올때 까지 토큰 생성
- 이렇게 생성된 모든 데이터들의 집합을 D*로 표기
- Step 4에서 필터링 되므로, 레이블 별 생성하고 싶은 수의 10배를 생성함
-
총 생성되는 데이터의 수는 :
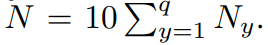
- Step 4: Filter synthesized data
- 생성된 데이터들은 노이즈 및 에러가 존재하여 성능향상에 장애물이 됨
- 이러한 데이터들을 없애기 위해 생성된 모든 데이터 D*를 Step 1에서 학습한 classifier h를 이용하여 필터링 함
- 각 클래스 y마다 classifier h로 부터 얻은 confidence score 상위 \(N_y\) 개의 데이터만을 사용함
- 이렇게 얻어진 데이터셋을 \(D_{synthesized}\) 로 표기
- 이러한 방식은 semi-supervised learning 에서 가져왔다고 함
- 또한 제안한 방식은 double voting mechanism이 적용된다고 함
- (생성할때 condition으로 label 정보를 주고, Filter를 통해서 label confidence로 filtering 하므로 double voting mechanism 이라고 하는 것 같음)
5. Experimental Results
3종류의 classifier (BERT, SVM, LSTM) 를 3종류의 데이터셋 (ATIS, TREC, WVA) 에 대하여 class 당 다양한 양의 데이터로 테스트함.
또한 LAMBADA를 다른 data augmentation 기법 (CVAE, EDA, CBERT)와 비교함
5.1 Datasets
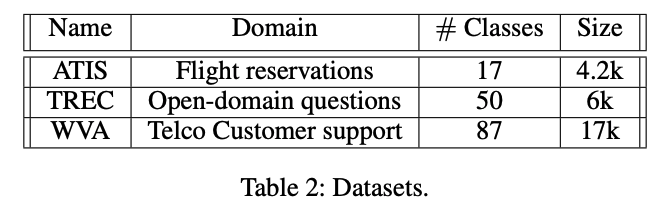
- Airline Travel Information Systems (ATIS) : 비행 관련 정보에 관한 데이터 셋, 대부분의 데이터가 flight class에 속하는 imbalanced dataset.
- Text Retrieval Conference (TREC) : Open-domain, fact-based questions으로 question classification dataset.
- IBM Waston Virtual Assistant (WVA) : Chatbot system을 위한 intent classification dataset.
Dataset을 train, validation, test sets (80%, 10%, 10%) 으로 랜덤하게 나누어 사용
Training set에서 각 클래스 별 5, 10, 20, 50, 100 개의 sample을 랜덤하게 추출하여 subset을 만들어 사용
5.2 Classifiers
자세한 내용은 논문 참조
- SVM : IBM Waston Natural Language Classifier 사용. 상대적으로 적은 데이터셋에서도 잘 작동함.
- LSTM : We implemented a sequence-to-vector model based on an LSTM component followed by two fully connected layers and a softmax layer. For word embedding, we employed GLoVe of 100 dimensions.
- BERT : Wiki & BooksCorpus (800 M words) 를 사용하여 Masked Language Model, next-sentence prediction task로 pre-trained 된 모델 사용
5.3 Generative Models
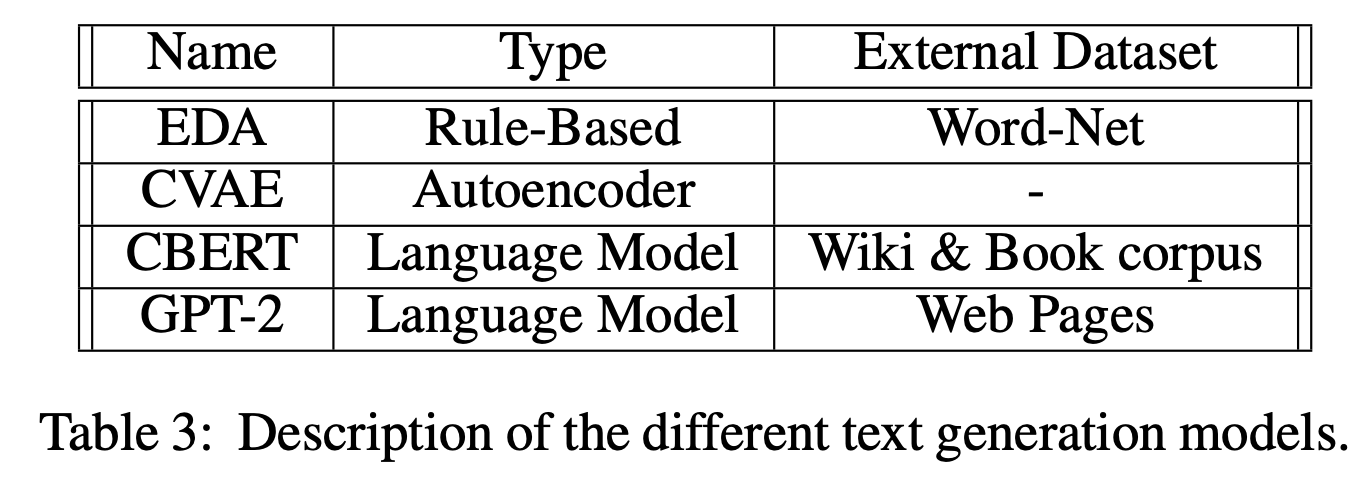
Fair comparison을 위해 class label을 이용하여 문장을 생성할 수 있는 conditional generative model을 사용함
- EDA : Easy Data Augmentation - Simple rule-based data augmentation for text. 동의어 치환, 랜덤 삽입, 랜덤 스왑, 랜덤 삭제를 사용
- CVAE : Conditional Variational Autoencoder - standard CVAE model with RNN-based encoder and decoder 를 사용
- CBERT : Conditional Bidirectional Encoder Representations from Transformers - pre-trained BERT 에 fine-tune을 하고 label condition을 주어 labeled sentence를 생성하는 방식
5.4 Results
Number of Samples and Classifiers
We compared the LAMBADA approach with the baseline using three different classifiers over varied numbers of trained samples: 5, 10, 20, 50, and 100 for each class. We used the ATIS dataset to discover for which sample size our approach is beneficial.
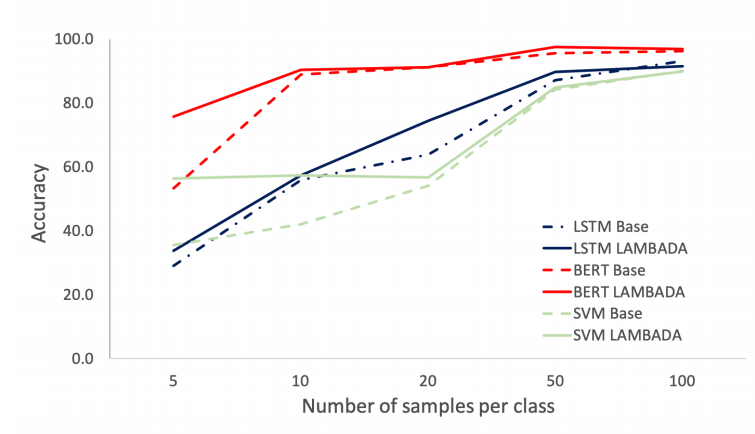
모든 classifier에 LAMBADA를 적용한 것이 클래스 당 sample size가 50이하일 때 좋음.
클래스 당 sample size가 100개일때는 LSTM과 SVM에서는 성능이 저하됨.
Datasets
We substantiate previous results by comparing the baseline to our LAMBADA approach over three datasets using five samples for each class. Table 4 shows that our approach significantly improves all classifiers over all datasets.
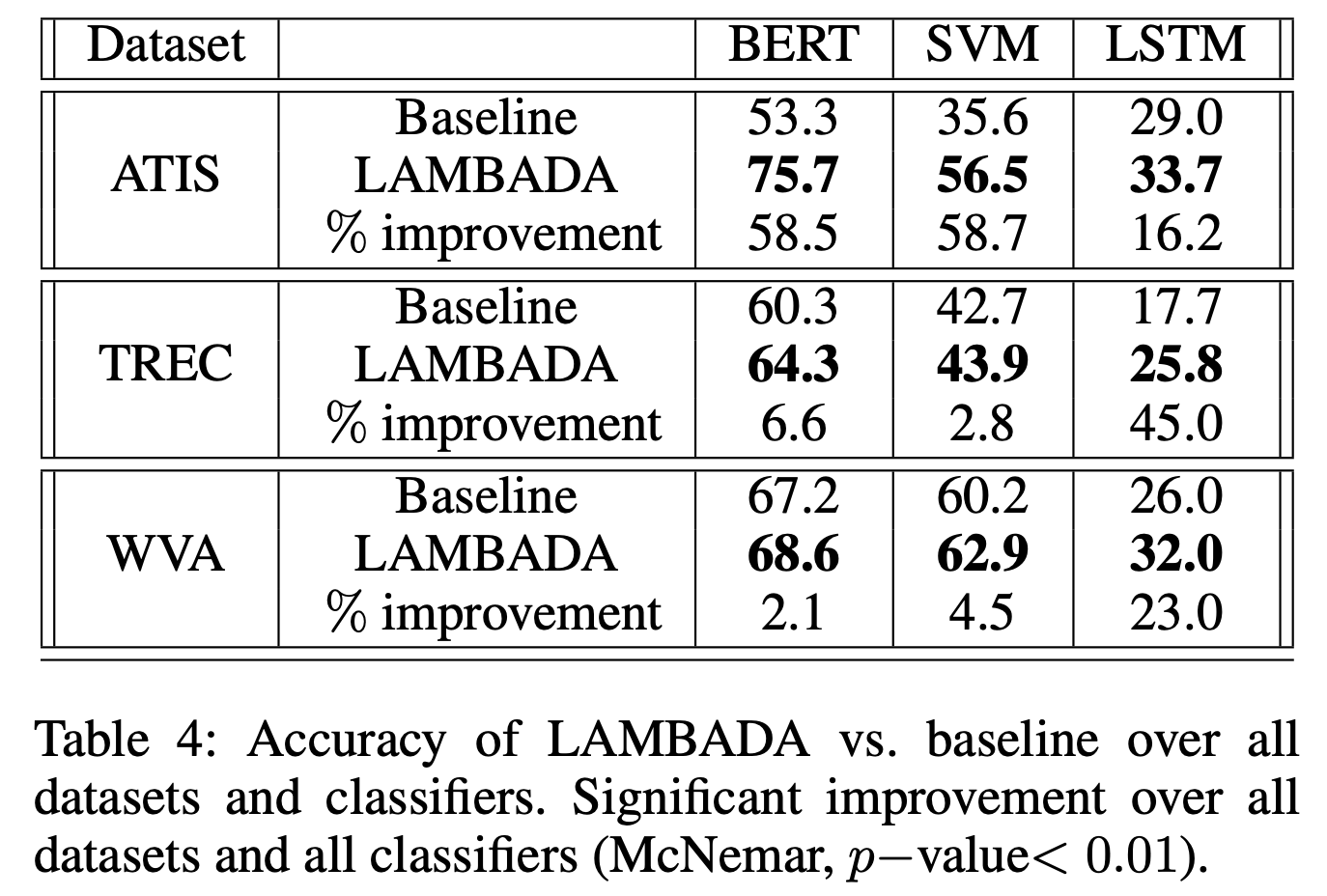
ATIS dataset에서 성능향상이 많이 보이는데 이는 imbalanced dataset에서 효과가 좋음을 암시
Comparison of Generative Models
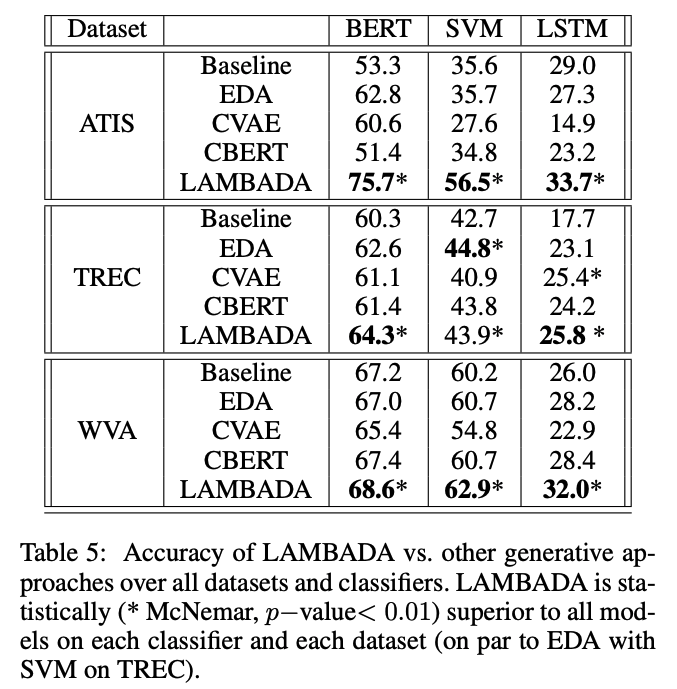
Table 5 shows that our approach is statistically superior to all other generation algorithms in the ATIS and WVA datasets over all classifiers.
❓ LAMBADA vs. Unlabeled Data
LAMBADA는 unlabeled data가 필요하지 않음
Unlabeled data를 사용하였을 떄와 LAMBADA (generation)을 사용하였을 때 비교
Unlabeled data는 semi-supervised approach (Ruder and Plank 2018) 방식을 사용
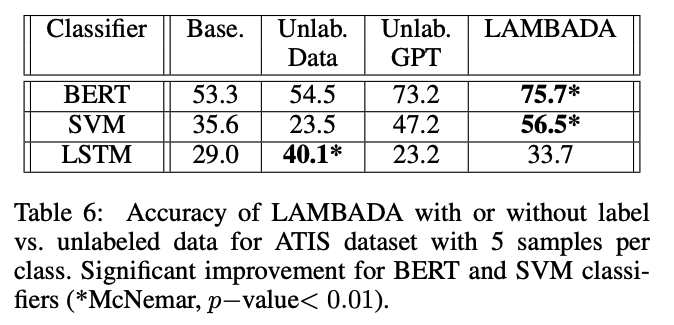
Unlabeled dataset을 만들기 위해 original dataset에서 label 정보를 무시한채 임의로 추출함
Weak labeling approach를 적용하기 위해 labeled dataset에 학습된 classifier를 이용하여 classification.
LAMBADA가 성능 향상에 더 도움이 되는걸로 보아 original dataset에서 weak labeling하여 사용하는 것 보다 generation 하여 데이터를 추가하는 것이 더 효과적임
성능 향상에 2가지 요인
- LAMBADA uses its “generated” labels, which significantly improve performance.
- LAMBADA allows us to control the number of samples per class by investing more effort in generating samples for classes that are under-represented in the original dataset.
“Generated” labels의 중요성을 평가하기 위하여 제거하고 실험을 해봄 (Unlab. GPT)
❓
Semi-supervised approach = weak labeling approach
Unlabeled dataset / classifier를 training 할때 사용되는 data 비율
"Generated" labels 의미
Unlab. GPT 는 마찬가지로 weak labeling approach를 해서 labeling을 하였는지
6. Discussion and Future Work
We introduce LAMBADA for improving classifiers’ performance. It involves fine-tuning a language model, generating new labeled-condition sentences and a filtering phase. We showed that our method statically improves classifiers’ performance on small data sets. In addition, we showed that LAMBADA beats the state-of-the-art techniques in data augmentation.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA