Data Augmentation using Pre-trained Transformer Models
- 9 minsAuthors : Varun Kumar, Ashutosh Choudhary, Eunah Cho
Alexa AI (amazon)
Arxiv
Paper : https://arxiv.org/pdf/2004.12239.pdf
Code : https://github.com/varinf/TransformersDataAugmentation (TBD)
Summary
- PLM (BERT, GPT2, BART) 를 이용한 Conditional Data augmentation 실험 및 분석
- Classification task에서 1%의 데이터로 실험 진행, BART (seq2seq) 가 가장 높은 성능을 보임
- 다양한 방법으로 실험을 하였으며, EDA와도 비교를 함
- Extrinsic, intrinsic 평가를 통해 생성된 데이터가 label 정보를 어느정도 반영했는지, Diversity에 대한 분석도 존재함
개인적 견해
- 모델별 파라미터 사이즈가 통일되지 않아 unfair한 느낌
- GPT2의 경우 데이터가 하나인가?
- Generative model based data augmentation은 아직 갈길이 멀다
- Pratical guideline은 쓸모가 있어보인다
- 코드가 아직 공개되지 않음 ☹️
Abstract
Language model based pre-trained models such as BERT have provided significant gains across different NLP tasks. In this paper, we study different types of pre-trained transformer based models such as autoregressive models (GPT-2), auto-encoder models (BERT), and seq2seq models (BART) for conditional data augmentation. We show that prepending the class labels to text sequences provides a simple yet effective way to condition the pre-trained models for data augmentation. On three classification benchmarks, pre-trained Seq2Seq model outperforms other models. Further, we explore how different pretrained model based data augmentation differs in-terms of data diversity, and how well such methods preserve the class-label information
1. Introduction
- Data augmentation (DA) 는 training data를 늘리기 위해 사용되며, 이러한 행동은 loew-data regime tasks에서 근본적으로 overfitting을 방지하거나, 모델을 강건하게 만든다.
- Natural Language Processing (NLP) 분야에서 WordNet을 사용한 word replacement 기반이 사용된 EDA가 classification task에서 성능향상을 보였으며 Language model을 기반으로 한 DA 방법도 연구가 되었음
- 하지만 이러한 방법론들은 클래스 레이블을 보존하는데 어려움이 있다.
- 예를 들면, Text classification task에서 “a small impact with a big movie” 라는 데이터로 부터 “a small movie with a big impact” 라는 문장이 만들어 질 수 있다.
- 이러한 문제를 해결하기 위해 label embedding을 활용한 Conditional BERT (CBERT) 가 제안되기도 하였으며, GPT2를 이용한 DA에서 class를 condition으로 제공하여 생성하는 방법도 제안되었다.
- 이 페이퍼에서는 pre-trained transformer 계열의 모델들을 활용한 DA 방법론에 대해 연구한다.
- Auto-regressive (AR) LM : GPT2
- Autoencoder (AE) LM : BERT
- Seq2Seq2 model : BART
- 해당 모델들을 바탕으로 sentiment classification, intent classification, question classification task들에 대해 실험을 하며, DA의 효과를 좀 더 확실하게 보기 위해 low-resource data scenario (only 1% of the existing labeled data)를 구성한다.
- 결과적으로는 pre-trained transformer 계열 모델을 활용한 DA 방식은 효과가 있으며, seq2seq model (BART) 은 label 정보를 유지하며 다양한 데이터를 생성하여 가장 좋은 효과를 보여 주었다.
- Contribution
- Implementation of a seq2seq pre-trained model based data augmentation
- Experimental comparison of different conditional pre-trained model based data augmentation methods
- A unified data augmentation approach with practical guidelines for using different types of pre-trained models.
2. DA using Pre-trained Models
- AE setting : 입력 문장에 존재하는 임의 토큰에 대해 masking 한 후 모델이 mask 토큰을 예측 하도록 학습
- AR setting : 주어진 context를 바탕으로 모델이 next word를 예측 하도록 학습
- seq2seq setting : Denosing AE tasks 학습

DA Problem formulation
- \(D_{train} = \{x_i,y_i\}^1_n, \ where\ x_i=\{w_j\}^1_m\) : m 개의 단어로 이루어져 있는 학습 데이터, \(y_i\)는 label
- G : Pre-trained model
- \(D_{synthetic}\) : 생성된 데이터셋
- Algorithm 1이 생성 프로세스를 나타냄
- 모든 방법론에서 학습 데이터당 1개의 데이터만 augmentation 함, 즉 augmented data는 original data와 수가 같음
2.1. Conditional DA using Pre-trained LM
- DA를 위해 Label information 을 이용하여 fine-tuning한 모델은 CBERT가 존재하지만 해당 paper에서는 segment embedding을 label embedding으로 대체하여 사용하였기에 해당 방법은 다른 LM에서 일반적으로 사용되지 못함
- 따라서 아래와 같은 두가지 방법으로 Pre-trained LM에 class label information을 활용함
-
prepend : 각 sequence \(x_i\)에 \(y_i\)를 앞쪽에 붙여서 사용한다. 이때, \(y_i\)는 model의 vocab에 따로 추가하지 않아서 subword로 split이 될 수 있다
ex) Pos ##istive [SEP] The movie is [MASK]
-
expand : 위와 같은 방식이지만 \(y_i\)를 model의 vocab에 추가하여 사용한다
ex) Positive [SEP] The movie is [MASK]
-
- Transformer based LM 구현은 huggigngface transformers를 이용했다고 함
2.1.1. Fine-tuning and generation using AE LMs
- AE model로 BERT를 채택
- Fine-tuning objective 도 기존 BERT와 동일하게 masked language model task 방식 채택
2.1.2. Fine-tuning and generation using AR
- AR model로 GPT2를 채택
-
Fine-tuning을 위해 \(D_{train}\)에 존재하는 모든 데이터를 다음과 같이 concating 함
\[y_i\ SEP\ x_i\ EOS\ y_2\ ...\ y_n\ SEP\ x_n\ EOS\] - SEP는 label과 sentence를 구분하는 separation token, EOS는 end of sentence token
- Generation을 할때는 \(y_i \ SEP\) 를 context로 주고 생성을 시작해서 \(EOS\) 토큰이 나올때 까지 생성을 한다.
- 하지만 위와 같은 방법은 실험을 통해서 label information을 유지하기 어려웠으며, 간단하지만 좋은 개선 방법인 \(y_i \ SEP \ w_i \ .. \ w_k\) 방식을 사용하였다. 이때 \(w_1 \ .. \ w_k\) 는 \(x_i\) 의 시작 \(k\) 개의 word 이며, 실험에서는 k = 3 을 사용하였고 이와 같은 방법을 \(\text{GPT2}_\text{context}\)라고 부를 것이다.
2.2. Conditional DA using Pre-trained Seq2Seq model
- Seq2seq model로 BART를 채택 (T5도 존재하지만 computation cost가 비싸기 때문에 채택하지 않음)
2.2.1. Fine-tuning and generation using Seq2Seq BART
- 다른 Pre-trained LM과 동일하게 label을 prepending 하여 사용
- BART의 training objective가 다양하게 존재하는데 가장 성능이 좋은 masking task를 사용
- Masking 같은 경우 word level 과 subword level 에 적용이 될 수 있지만, 실험 상 subword level masking의 경우보다 word level masking이 성능이 더 좋기 때문에 word level을 사용한다
- 아래 두가지 방법으로 masking을 적용함
- \(\text{BART}_{word}\) : \(w_i\) 를 \(<mask>\) 를 통해 단순 masking
- \(\text{BART}_{span}\) : 연속된 k 개의 chunk (\(w_i, w_{i+1}..w_{i+k}\))를 하나의 \(<mask>\) 로 치환한다 (SpanBERT 와 유사)
- Masking은 전체 토큰의 20% 에 적용함
- 인코더에서는 masked sentence를 인코딩하여 decoder로 넘겨주고 decoder는 이를 원래 sentence로 복원하도록 학습
- 하이퍼파라미터는 validation set의 성능을 통해 결정함
2.3 Pre-trained Model Implementation
2.3.1. BERT based models
- Huggingface transformers의 “bert-base-uncased” 모델을 이용 (110M)
- prepend setting 에서는 10 epochs 학습하고 dev set으로 최적의 모델 선택, learning rate = 4e-5
- expand setting 에서는 150 epochs 학습해야 converge 함.
- Label word가 새롭게 initializing이 되어서 더 오래 학습해야 된다고 함
- Learning rate 는 SST, TREC 에서는 1.5e-4, SNIPS 에서는 1e-4 를 사용
2.3.2. GPT2 model implementation
- Huggingface transformers의 GPT2-Small model을 사용 (117M)
- \(SEP\) token을 \(<\|endoftext\|>\) token 으로 사용
- \(top_k = 0\), \(top_p = 0.9\) 인 nucleus sampling을 사용
2.3.3. BART model implementation
- Fairseq toolkit에 구현된 BART Large 모델을 사용 (400M)
- BART model vocab에는 이미 \(<mask>\) token이 존재하여 그것을 이용하여 20% masking 함
- Decoder에서 masking 된 \(x_i\)를 예측하며, \(y_i\)도 예측할 수 있음
- label-smoothing, beam size 5의 beam search 사용
- BART 모델에만 f16 precision 사용
3. Experimental setup
3.1. Baseline Approaches for DA
- EDA : A simple effective word-replacement based augmentation method
- CBERT : The latest model-based augmentation that outperforms other word-replacement based methods
3.2. Data Sets
- SST-2 : A dataset for sentiment classification on movie reviews, which are annotated with two labels (Positive and Negative)
- SNIPS : A dataset contains 7 intents which are collected from the Snips personal voice assistant
- TREC : A fine grained question classification dataset sourced from TREC. It contains six question types.
- 세가지 모델들은 모두 다른 byte pair encoding을 사용하므로, prepend의 경우 label이 각각 다르게 subword로 분리 될 수 있다
- Table 1 에서 각 데이터셋의 Label Name을 확인할 수 있다

3.2.1. Low-resource data scenario
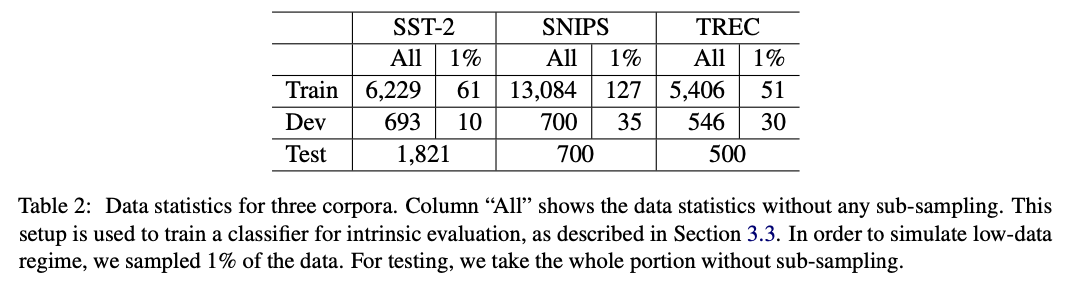
- 모든 데이터 셋에 대해 Training dataset의 경우 1%만 랜덤 추출하여 사용
- Validation dataset의 경우 각 label 당 5개를 추출하여 사용
- 데이터 통계는 Table 2 참조
3.3. Evaluation
- Extrinsic evaluation 과 Intrinsic evaluation을 진행
- Extrinsic evaluation : Low-data regime training data에 생성된 데이터를 추가하여 성능 확인
- Intrinsic evaluation
- Semantic fidelity : 생성된 데이터가 원래 의미와 label 정보를 유지하는지 평가 - 기존 task의 training set과 test set을 합쳐 BERT를 학습 시킨 후 classification 하여 평가
- Text diversity : 생성된 데이터들의 diversity를 type token ratio를 이용하여 평가 - Unique token의 비율
3.3.1. Classifiers for intrinsic evaluation
- 3.3 에서 언급한 방식으로 진행, dev set으로 가장 좋은 모델 선정
- 선정된 모델로 생성된 데이터에 대해 평가 하는 방법
- Dev set에 대해 선정된 모델의 성능은 다음과 같음

4. Results and Discussion
4.1. Generation by Conditioning on Labels
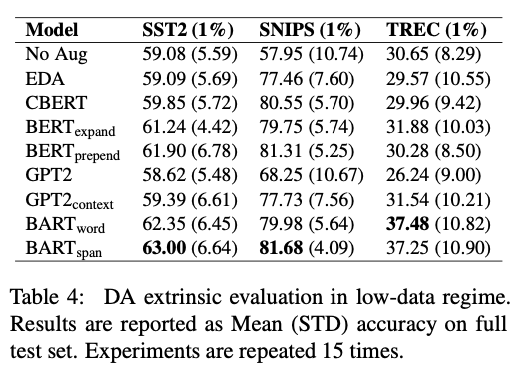
- 실험 결과 expand 보다 prepend가 더 좋다고 판단하여 모든 모델에 prepend로 사용하여 실험 진행
- Extrinsic evaluation 결과는 다음과 같음
4.2. Pre-trained Model Comparison
- BART 기반이 가장 좋음
- GPT2는 context를 주면 좋음
- 재현이 잘 되지 않음
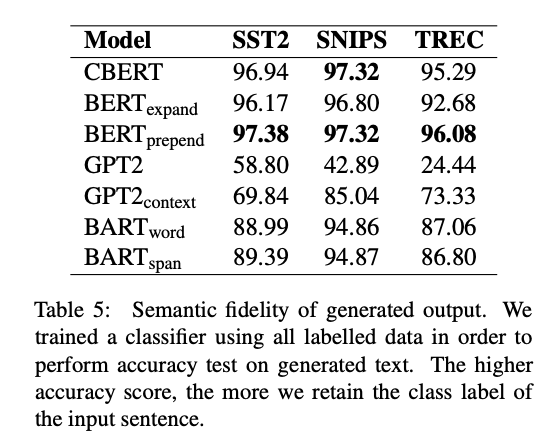
Generated Data Fidelity
- \(\text{BERT}_\text{prepend}\)가 가장 좋음
- GPT2와 같은 AR 모델을 label 정보를 유지하며 생성하기 어려움을 보임
- Data fidelity 가 높으면, diversity가 작아서 instrinsic evaluation에서는 좋은 성능을 이끌어 내지만 extrinsic evaluation에서는 꼭 그렇지는 않다고 판단
- 해당 평가 결과는 아래와 같음
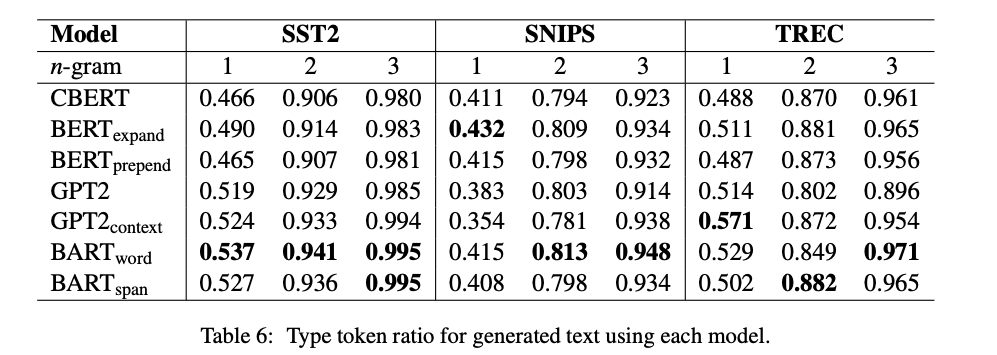
Generated Data Diversity
- Type token ratio는 BART가 uni-, bi-, tri- gram에 대해서 대부분 높게 평가 되었다.
- 그 만큼 BART가 다양하게 생성한다고 판단할 수 있다
- 실험 결과는 아래와 같다
4.3. Guidelines For Using Different Types Of Pre-trained Models For DA
- AE models : Label prepending 방식을 사용하고 Large model을 사용하면 성능 향상 된다
- AR models : Context token에 label과 단어를 조금 주어서 생성을 하면 좋다
- Seq2Seq models
- 다양한 masking 전략 중 span masking이 가장 성능이 좋음
- AE 모델은 생성되는 문장의 길이가 제한되지만 레이블을 보존 잘하고 반면 AR 모델은 길이 제한은 없지만 레이블 보존을 잘 하지 못한다
- Seq2Seq 모델은 AE 모델과 AR 모델의 균형을 잘 이룬 모델이라고 볼 수 있다
5. Conclusion And Future Work
We show that AE, AR, and Seq2Seq pre-trained models can be conditioned on labels by prepending label information and provide an effective way to augment training data. These DA methods can be easily combined with other advances in text content manipulation such as co-training the data generator and classifier (Hu et al., 2019). We hope that unifying different DA methods would inspire new approaches for universal NLP data augmentation.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA