CTRLsum: TOWARDS GENERIC CONTROLLABLE TEXT SUMMARIZATION
- 8 minsAuthors : Junxian He (CMU), Wojciech Krys ́cin ́ski, Bryan McCann, Nazneen Rajani, Caiming Xiong (Saleforce Research)
Arxiv 2020
Paper : https://arxiv.org/pdf/2012.04281.pdf
Code : https://github.com/salesforce/ctrl-sum
Summary
- BART 를 fine-tuning 할 때 keyword를 추가 함으로써 요약을 잘 하게끔 만들어줌
- 그 과정에서 keyword를 automatic하게 extraction하는 방법을 제안함
- 따라서 unseen control code에 대응할 수 있음
개인적 견해
- Unseen control code에 대응할 수 있지만 비교 대상의 모델 사이즈가 비슷하지 않아 조금 아쉬운 부분이 있음
Abstract
Current summarization systems yield generic summaries that are disconnected from users’ preferences and expectations. To address this limitation, we present CTRLsum, a novel framework for controllable summarization. Our approach enables users to control multiple aspects of generated summaries by interacting with the summarization system through textual input in the form of a set of keywords or descriptive prompts. Using a single unified model, CTRLsum is able to achieve a broad scope of summary manipulation at inference time without requiring additional human annotations or pre-defining a set of control aspects during training. We quantitatively demonstrate the effectiveness of our approach on three domains of summarization datasets and five control aspects: 1) entity-centric and 2) length-controllable summarization, 3) contribution summarization on scientific papers, 4) invention purpose summarization on patent filings, and 5) question-guided summarization on news articles in a reading comprehension setting. Moreover, when used in a standard, uncontrolled summarization setting, CTRLsum achieves state-of-the-art results on the CNN/DailyMail dataset.
1. Introduction
- 요약 시스템에는 크게 두가지 범주가 있음
- Extractive summarization
- Abstractive summarization
- 더 유연하고 일관되고 유창한 요약을 생성할 수 있음.
- 본 논문에서는 Abstractive summarization에 중점을 둠
- 요약의 경우 사용자의 선호와 관련된 정보를 포함해야하지만 일반적으로는 포함된 정보를 단순 요약함
- 예를 들어 아래와 같은 figure 1 에서 Lebron James나 Stephen Curry와 같은 특정 농구 스타 팬들은 해당 선수가 치른 경기에만 관심이 있을 수 있으며, 선수의 점수를 알고 싶어 할 수 있음
- 사용자가 모델에서 요약을 컨트롤 할 수 있는 제어 가능한 요약에 중점을 둠
- Keyword 또는 descriptive prompts로 이루어진 control token을 통해 요약하는 CTRLsum을 제안
- CTRL을 포함한 다른 여러 방식과는 달리 학습을 위해 추가적인 human annotation이나 pre-defining control code가 필요하지 않음.
- 따라서 test step에서 unseen control code에 대해 일반화 시킬 수 있음
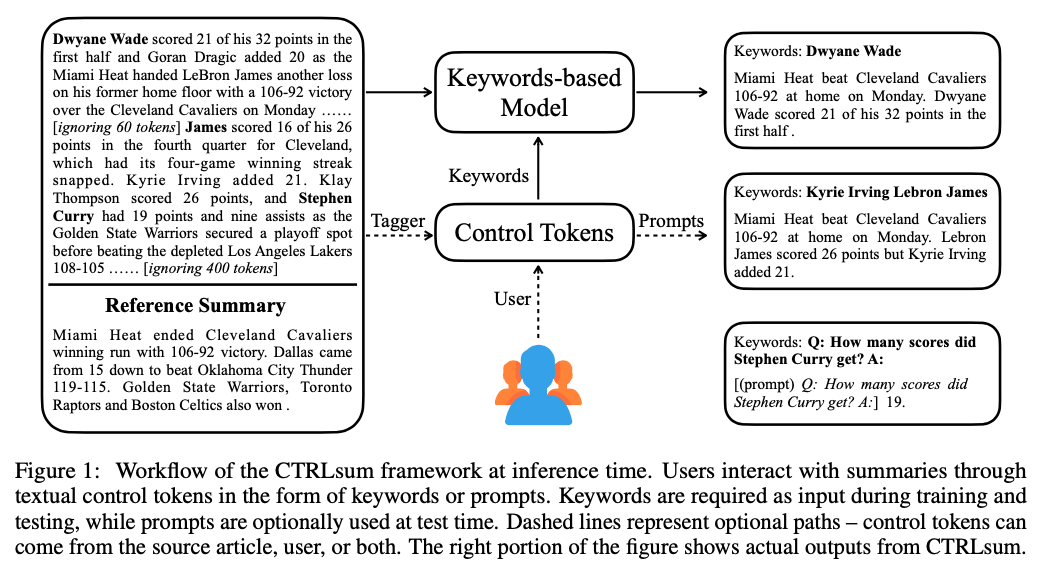
2. CTRLsum
2. 1. Overview
- 일반적인 요약 방법은 Conditional distribution \(p(y\vert x)\) 을 학습함
- where x and y represent the source document and summary respectively
- 이를 컨트롤 하기 위해 control token \(z\) 를사용하여 \(p(y\vert x,z)\)를 예측하는 요약 모델을 학습하는 것을 제안
- Control code z는 keyword 또는 prompt를 포함하거나 둘의 조합 형태이고 이를 통해 명시적으로 제어 가능
2. 2. Automatic Keyword Extraction
- 모델을 훈련하기 위해 훈련 데이터에서 키워드를 추출함
- 그외에도 CTRLsum은 test time에 자동으로 키워드 추출 메커니즘을 가지고 있어 사용자 선호도에 따라 자동 키워드를 제안하거나 사용자의 cotrol 없이 요약을 수행 할 수 있음
- 아래는 각 스텝 별 키워드 추출 방법에 대한 설명
Training
- Ground-truth summary에 대해 ROUGE score를 최대화 하는 sentence를 document에서 선택하여 중요한 문장만을 키워드 후보로 제한하도록 함
- 그런 다음 Ground-truth summary의 sub-sequences와 일치하는 문장중 가장 긴 sub-sequence를 선택함.
- 마지막으로 중복 단어와 stop words를 제거하고 나머지 토큰은 키워드로 유지함
- 이는 입력과 대상 사이에 신뢰할 수 있는 상관 관계를 구축함으로써 주어진 키워드에 대한 의존성을 만들어줌.
- 또한 사용자가 제공한 키워드가 test time에서 무시되지 않도록 함
Inference
- Test time에서의 keyword extraction problem을 sequence labeling task로 품
- Training dataset의 keyword와 document에 대해 BERT-based sequence tagger를 학습함
- 해당 Tagger는 Test document에서 각 token에 대한 selection probability \(q_j\)를 계산함
- Training time extraction과 유사하게, 먼저 highest average token seslection probability를 갖는 \(n_s\) 문장을 선택함
- 이 문장 내에서 \(q_j > ε\) 인 단어를 최대 \(m_{max}\) 수까지 키워드로 선택함
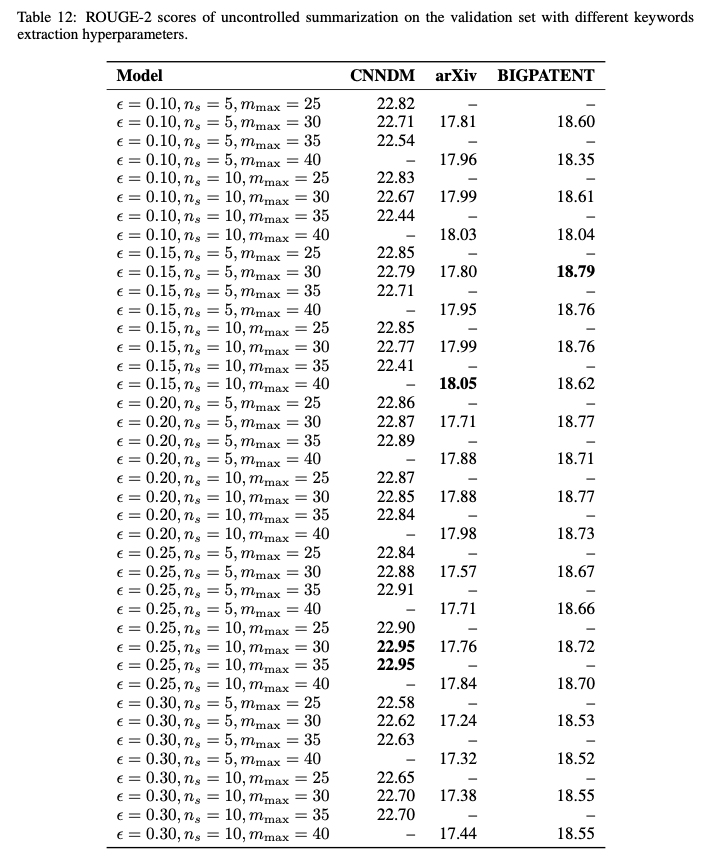
- \(n_s, ε, m_{max}\) 는 hyper-parameters이며 실험 테이블은 table 12에 존재
-
Table 12
2. 3. Summarization: Training Details
-
Foramt : Trining time에서 special token (“|“)으로 분리된 keyword sequence를 source document 앞에 추가함
서로 다른 문장에서 가지고 온 키워드 일 경우 “|” 를 통해 분리
-
Keyword dropout: 2.2에서 얻어지는 키워드의 경우 소스 문서의 요약에서 대부분 단어를 그대로 유지함.
따라서 이러한 키워드에 의존성이 높아 모델이 요약에서 새로운 단어를 생성하지 않을 수 있음
이 문제를 해결하기 위해 모델 입력에 있는 키워드에 의존하는 방법을 배우는 동시에 키워드에 없는 소스 문서의 주요 정보를 전달하도록 training time에서 키워드를 무작위로 dropout을 함
2. 4. Summarization: Inference with Keywords
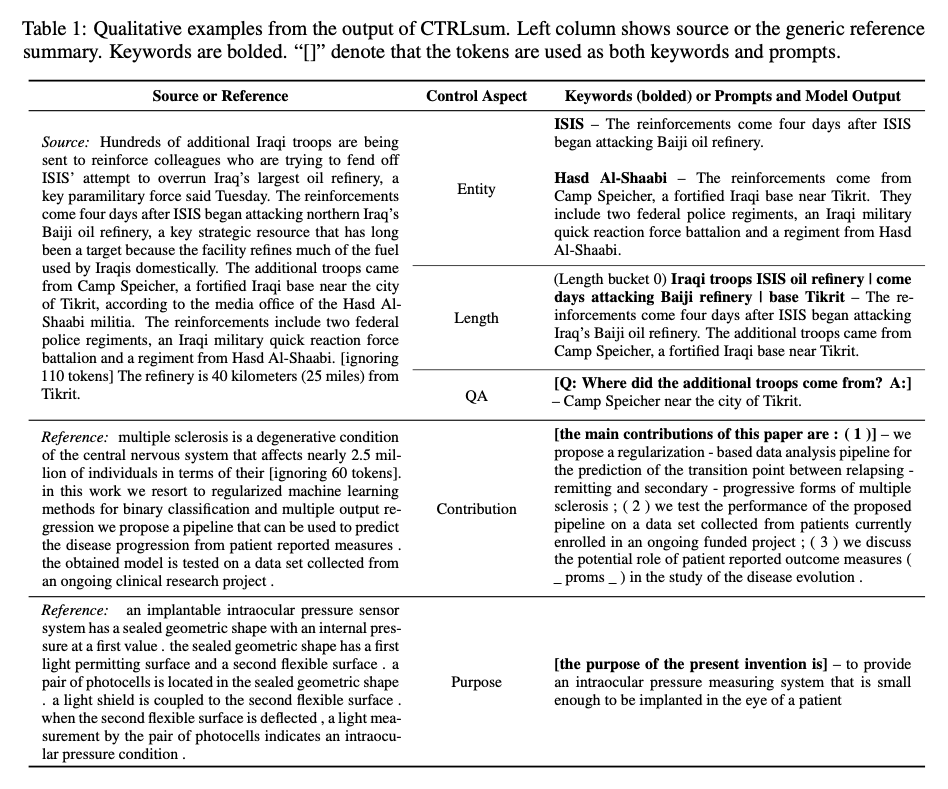
기학습된 CTRLsum은 추가적인 fine-tuning 없이 새로운 use cases에 대응할 수 있음
예를 들어 훈련 중에는 entity 또는 length 에 대해 특별히 초점을 맞추지는 않았지만 제어가 가능함
- Entity Control : 관심이 있는 엔티티에 초점을 맞추어 요약하는 것 (Figure 1.)
- Length Control : 요약 길이를 사용자가 지정하는 것
- 학습 데이터를 요약 길이 별로 \(l\)개의 bucket으로 분리하고 각 버킷에 대해 평균 키워드 수 \(k_l\)을 계산함
- Test time에서 사용자가 정한 매개변수 \(l \in \{0,1,2,3,4\}\)를 지정하여 시퀀스 태거가 계산 한 확률이 가장 높은 \(k_l\) 개의 키워드를 포함함
2. 5. Summarization: Inference with Keywords and Prompts
요약 시스템에서 처음으로 Prompt 기반 제어 방법을 사용 및 평가함 각 요약에 대한 Prompt :
- Summarizing Contributions (Paper) : “the main contributions of this paper are:(1)”
- Summarizing Invention Purpose (Patent article) : “the purpose of the present invention is”
- Question-guided summarization : “Q: question text? A:”
3. Related Work
Previous work on controllable summarization often collects control codes such as entity or length as supervision to train the model conditioned on both the code and article together (Fan et al., 2018; Liu et al., 2018). These methods do not generalize for controlling aspects of the summarization that were not seen during training. Recently Saito et al. (2020a) use the number of word prototypes to control summary length in a similar way to how we use keywords. Interactive summarization provides a way for users to continuously control the information that is included in the summary (Bornstein et al., 1999; Leuski et al., 2003). More broadly, controllable text generation has been studied for styles (Hu et al., 2017; Fu et al., 2018; He et al., 2020b), topics (Tang et al., 2019; Huang et al., 2019), and templates (Guu et al., 2018; Wiseman et al., 2018; He et al., 2020a).
Keyword-guided text generation has been applied in other contexts with different motivations. Gehrmann et al. (2018) utilize copying words at test time to mask copying operations in a summarization task. Li et al. (2018) and Saito et al. (2020b) use keywords as extra input to improve the uncontrolled summarization performance. Wang et al. (2016), Mou et al. (2016), and Yao et al. (2019) use textual input to plan poetry, dialogue, and stories respectively. Lexically-constrained decoding specifies certain lexicons as hard constraints in the target text (Hokamp & Liu, 2017; Post & Vilar, 2018). Prefix-constrained decoding was used in machine translation (Knowles & Koehn, 2016; Wuebker et al., 2016) and also to demonstrate the multi-task ability present in large pretrained models (McCann et al., 2018; Radford et al., 2019; Keskar et al., 2019; Brown et al., 2020).
4. Experiments
4. 1. Experimental Details
- Datasets
- CNN/Dailymail (CNNDM) news articles
- arXiv scientific papers
- BIGPATENT patent articles
- Model
- CTRLsum : Pretrained BART-large
- Automatic keyword tagger : Pretrained BERT-large
4. 2. Entity Control
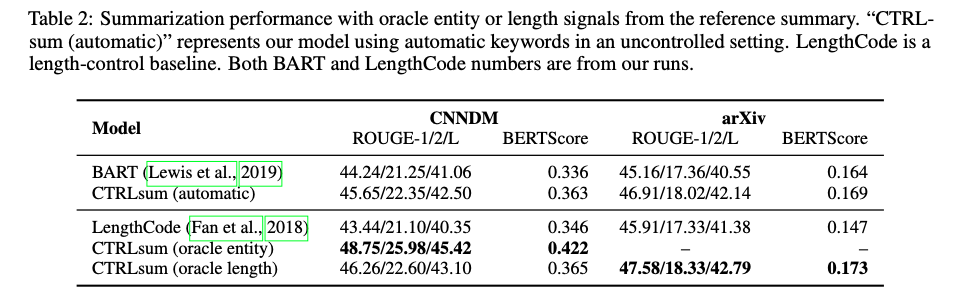
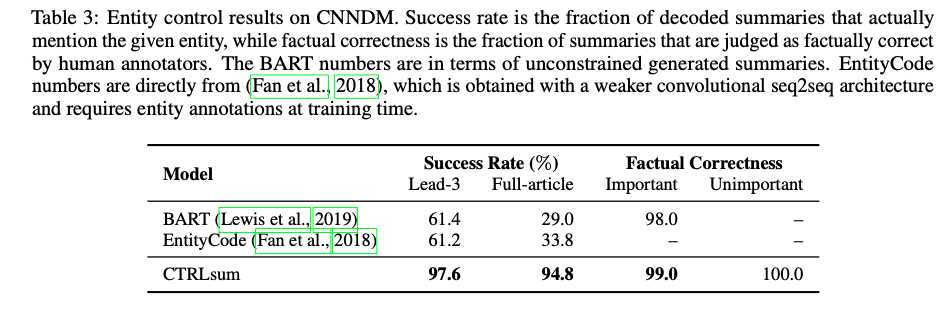
- Entity에 따른 요약이 잘 되는지에 대한 평가
- Oracle entity의 경우 ground-truth target으로 부터 추출된 entity를 사용해 요약한 것
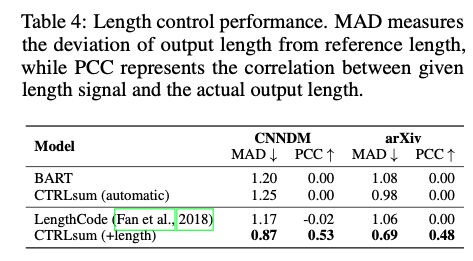
4. 3. Length Control
- 위의 Table 2 참조
4. 4. Contribution and Purpose Summarization

- arXiv paper에 대해 contribution 요약과 Patent article에 대한 purpose 요약 평가
- CTRLsum의 경우 키워드 관련 콘텐츠에 조금 더 초점을 맞춤
4. 5. Question-Guided Summarization

- Zero-shot 환경에서의 Reading comprehension benchamrk 평가
4. 6. Automatic Summarization
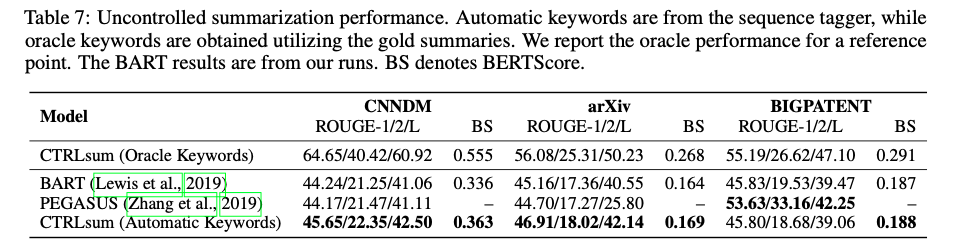
- user의 컨트롤 없이 자동으로 추출된 키워드 사용하여 요약하여 평가
- BIGPATENT에서는 차이가 나는데 그 이유로는 데이터셋 전처리 차이, sub-optimal learning schedule, BART 모델과 PEGASUS 모델의 고유한 차이로 인한 것일 수 있음
- PEGASUS-Large : 568M
4. 7. Human Evaluation
Controlled Summarization
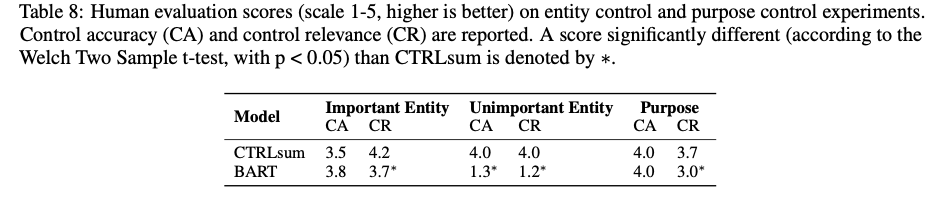
1 - 5 척도
- Control Accuracy (CA) : 요약 의도와 관련하여 주요 정보가 포함되어 있는지
- Control Relevance (CR) : 요약 의도와 전반적으로 관련이 있는지
Uncontrolled Summarization
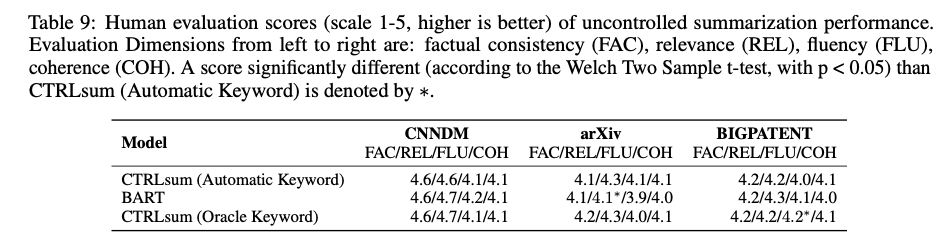
1 - 5 척도
- Factual Consistency (FC) : 소스 문서에 포함되어 있는 진술만을 포함
- Relevance (REL) : 원본 문서의 중요한 정보만을 포함
- Fluency (FLU)
- Coherence (COH)
실험 세팅 및 ablation statudy, 다양한 예제는 Appendix 참조
5. Conclusion
In this paper we propose a generic framework to perform multi-aspect controllable summarization. The model is conditioned on keywords to predict summaries during training. At inference time the control tokens, in the form of keywords or prompts, enable users to interact with models in a very flexible way. Experiments on five different control aspects demonstrate the efficacy of our method.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA