CoCon: A Self-Supervised Approach For Controlled Text Generation
- 9 minsAuthors : Alvin Chan, Yew-Soon Ong, Bill Pung, Aston Zhang, Jie Fu / Nanyang Tech, Amazon AI, Mila, Polytechnique Montreal
ICLR 2021 Poster
Paper : https://openreview.net/pdf?id=VD_ozqvBy4W
Code : -
Summary
- CoCon Block을 제안하여 전체를 tuning 하지 않고 해당 Block 만을 tuning 해 control 하는 방법 제안
- self-supervised learning approach로 다양한 loss로 더 나은 성능을 얻음
- 즉, GPT-2로 생성된 데이터로만 학습을 한다 (labeled data가 불필요)
- word/phrase level이 아닌 sequence level도 contents conditioning으로 사용 할 수 있게됨
- Generalization을 증가시킴
- CTRL, PPLM에 비해 성능이 좋음 (Human evaluation 도 좋다)
개인적 견해
- 앞으로는 PLM 전체를 학습시키기 보다는 일정 block을 학습시켜 control 하는게 대세가 될듯함
- 또는, prompt를 잘 구성하여 control 할 수 있을 것이라고 생각된다.
- Generative model의 controllability는 꾸준히 관심을 받으며 연구분야로 자리잡을 것이다.
Abstract
Pretrained Transformer-based language models (LMs) display remarkable natural language generation capabilities. With their immense potential, controlling text generation of such LMs is getting attention. While there are studies that seek to control high-level attributes (such as sentiment and topic) of generated text, there is still a lack of more precise control over its content at the word- and phrase-level. Here, we propose Content-Conditioner (CoCon) to control an LM’s output text with a content input, at a fine-grained level. In our self-supervised approach, the CoCon block learns to help the LM complete a partially-observed text sequence by conditioning with content inputs that are withheld from the LM. Through experiments, we show that CoCon can naturally incorporate target content into generated texts and control high-level text attributes in a zero-shot manner.
1. Introduction
- Text generation의 성능이 증가함에 따라 controllability에 대한 관심이 높아지고 있다.
- PLM을 target text attributes를 포함하여 scratch 부터 학습하기에는 비용이 크다. (CTRL)
- 반면 Finetuning으로 하기에는 control scope이 제한된다.
- PLM architecture를 변경하지 않고 컨트롤 할 수 있는 좋은 방법은 attribute model 을 이용하는 방법이존재한다. (PPLM)
- 하지만 topic이나 감정 같은 high-level text attribute에 대해서는 효과적이지만, 동일한 target attribute에 대해 매우 다른 내용을 가진 텍스트를 생성할 수 있으므로 보다 더 세밀하게 컨트롤 해야 한다.
- 위와 같은 문제점들을 해결하기 위해 Content-Conditioner (CoCon)을 제안한다.
- 기존 방식과는 달리 Text sequence 형태를 attribute로 사용할 수 있다.
- PLM과 CoCon Block 으로 구성된다.
- CoCon Block을 통해 content-conditioned representation 을 구해서 $\text{LM}_{\beta}$ (Decoder block)에 전달한다.
- CoCon block 학습을 위해 PLM을 통해 생성된 텍스트 샘플을 활용하여 학습하는 방식인 self-supervised learning을 제안한다.
- 더 좋은 성능을 위해 다양한 loss도 함께 사용한다.
- CoCon은 LM의 작은 부분이고 학습 시 PLM을 fine-tuning 하지 않기 때문에 비교적 학습이 저렴하다.
- Zero-shot 방식으로 주제 및 감정과 같은 수준에서 확장할 수 있다.
- Contents bias term을 이용해 강도를 조절할 수 있다.
- Contribution
- CoCon 제안
- Future token에 대한 정보가 주어졌을 때 텍스트 시퀀스를 완성시키는 방법의 Self-supervised learning approach 제안
- PPLM과 CTRL에 대해 비교
2. Related Work
- Conditional generative models with reinforcement learning and generative adversarial networks
- Control code를 이용한 generative models (CTRL)
- PLM을 fine-tuning 하지 않고 small ‘pluggable’ attribute models을 사용하는 방법 (PPLM)
- CoCon은 PPLM과 달리 high-level text attributes 를 넘어 content level 에서의 control을 목표로 함
- 또한 PPLM에서는 labeled data가 필요하지만 CoCon은 self-supervised learning을 하므로 필요 없음
3. Content Conditioner (CoCon)
- Motivation
- 기존 LM
- \(p(x)\) can be conditioned on target attributes or control code (\(\alpha\)) (PPLM, CTRL)
- Output texts는 local content (e.g., words/phrase) 보다는 global attribute (e.g., sentiment/topic)에 의해 컨트롤이 된다
- 또한 prompt text, target attribute 와 적합한 candidates가 많으므로 생성 과정에서 샘플링으로 인해 매우 다양하고 다른 텍스트가 나올 수 있다.
-
e.g.) target attribute : Positive
→ This movie is so much fun.
→ The restaurant’s pasta is fantastic.
→ Movie and Restaurant …
-
-
CoCon : content input c for more fine-grained control over text generation
\[p(x_t,...,x_l|x_1,...,x_{t-1}) = \prod_{i=t}^lp(x_i|\text{c}, \{x_1,...,x_{i-1}\}).\]- c 는 text generation의 condition이 되며, text sequence가 될 수 있다.
-
Model Architecture
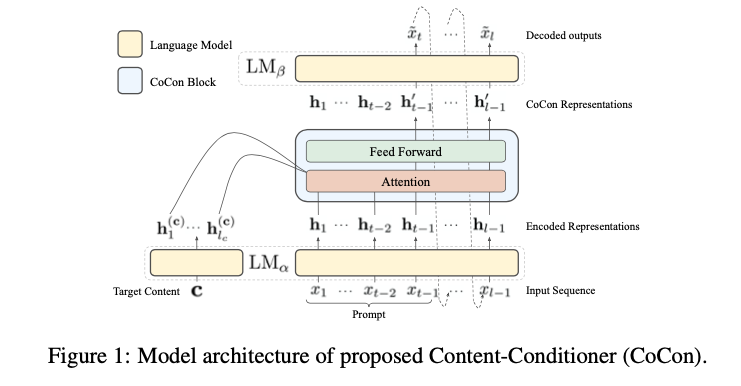
- CoCon block은 \(\text{LM}_{\alpha}\) (Encoder)와 \(\text{LM}_{\beta}\) (Decoder) 사이에 존재한다.
-
기존 logit :
\[o_{t} = \text{LM}(x_{:t-1}) = \text{LM}_{\beta}(\text{LM}_{\alpha}(x_{:t-1}))=\text{LM}_{\beta}(\text{h}_{:t-1})\] -
위 logit에서 h 를 다음 토큰을 control하는 매체라고 이해할 수 있다. 따라서 CoCon block을 통해 h 에 content input을 넣어 준다.
\[\text{h}'_{:t-1}=\text{CoCon}(\text{h}^{(c)}_{:l_c}, \text{h}_{:t-1})\] - where \(\text{h}^{(c)}_{:l_c} = \text{LM}_{\alpha}(c)\) is the content representations and \(l_c\) is the length of the content text sequence
- CoCon block은 아래와 같이 Attention 을 구하는 역할을 한다.
- \(\text{Q}, \text{K}, \text{V}\) = \(\text{LM}_{\alpha}\)에서 나온 \(\text{h}_{t-1}\) 의 query, key, value
- \(\text{K}^{(c)}, \text{V}^{(c)}\) = Content 에서 나온 \(\text{h}_{t-1}^{(c)}\) 의 key, value

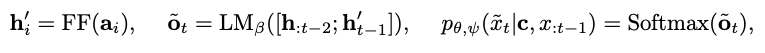
-
- CoCon block은 \(\text{LM}_{\alpha}\) (Encoder)와 \(\text{LM}_{\beta}\) (Decoder) 사이에 존재한다.
- Multiple Content Inputs
-
Multiple Content로 확장이 가능하다.
-
- Strength of Content Conditioning
- Attention weight (\(W\)) 를 조절하여 content의 영향력을 조절할 수 있음
3. 1. Self-Supervised Learning
CoCon의 Self-supervised learning approach는 자연어에서의 content의 다양성에 영감을 받음
Text sequence \(\text{x}=\{x_1,...,x_{t-1},x_t,...,x_l\}\) 이 주어지면 sequence를 쪼갠다.
\(\text{x}^a = \{x_1,...,x_{t-1}\}\), \(\text{x}^b = \{x_t,...,x_{l}\}\) where \(\text{x} = [\text{x}^a;\text{x}^b]\)
Real world에서는 \(\text{x}^a\)가 주어졌을 때 수많은 \(\text{x}^b\)가 나올 수 있다.
이는 샘플링 과정과 동반되어 \(\text{x}^b\)의 정보가 없으면 LM 만으로 \(\text{x}\)를 복원하기 힘들다는 것을 의미한다.

-
Self Reconstruction Loss
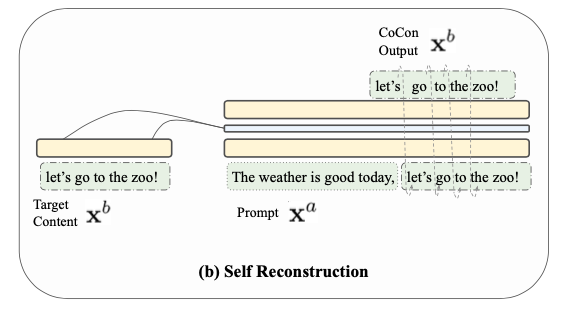
- 위의 intuition에 따라 CoCon block을 학습하기 위해 prompt를 \(\text{x}^a\), \(c=\text{x}^b\)로 두고 아래와 같은 식 (위에서 언급한 것과 같음)을 통해 학습을 한다.
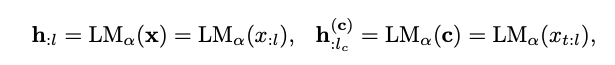
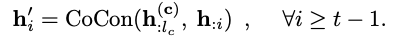
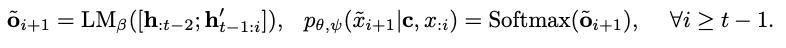
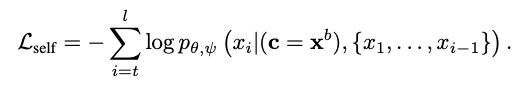
- Null Content Loss
- Self reconstruction 만으로 학습을 하면 \(\text{x}^b\)에 의존적 일 수 있으니 c = ∅ 을 통해 학습한다.
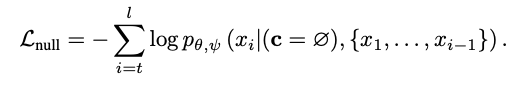
-
Cycle Reconstruction Loss
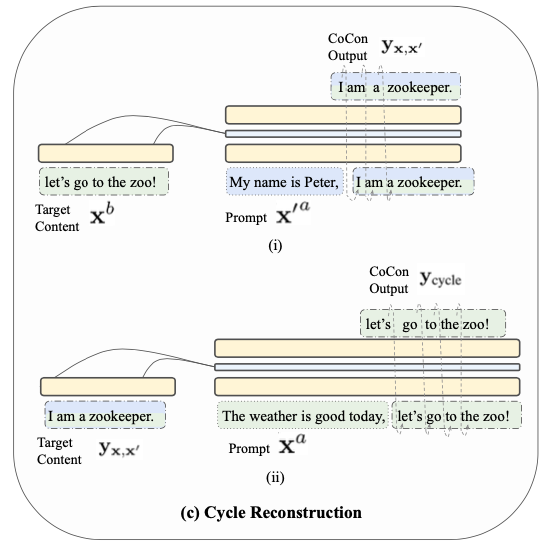
-
Content input (c) 와 Prompt text (p) 가 서로 다른 text sources에서 나올 수도 있으므로, generalization을 위해 Cycle Reconstruction loss를 추가한다.
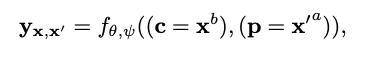
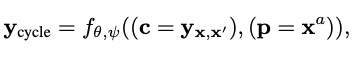
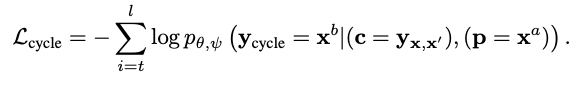
- Adversarial Loss
- Realistic한 text를 생성하도록 하기 위해 Reference sequence와 generated sequence를 이용하여 gan loss를 적용한다.
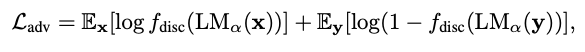
-
Full Training
To show that our approach is fully self-supervised and requires no manually labeled data fully, we use generated GPT-2 text samples as training data for all four training losses.
SGD:
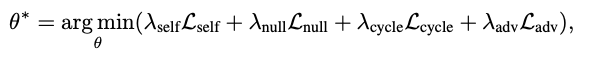
4. Experiments
- CoCon Setup
- GPT-2 medium 345M
- \(\text{LM}_{\alpha}\) : First 7 GPT-2 Transformer blocks
- \(\text{LM}_{\beta}\) : Remaining 17 blocks
- CoCon block’s architecture mirrors a single GPT-2 Transformer block
- Appendix A.
- Example


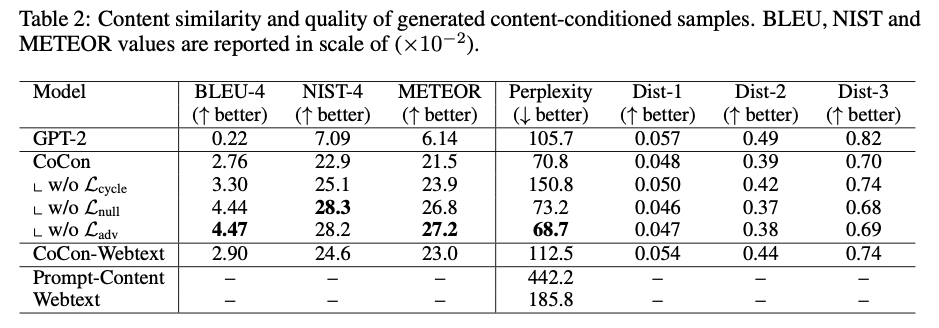
4. 1. Content Similarity
- 생성된 텍스트와 content input 인 c 를 통해 측정
- \(\mathcal{L}_{cycle}\) 을 제거하면 실제 생성되는 텍스트의 퀄리티가 떨어짐
- \(\mathcal{L}_{adv}\) 을 사용할 경우 diversity를 향상 시켜주지만 perplexity를 높아진다 (퀄리티 하락)
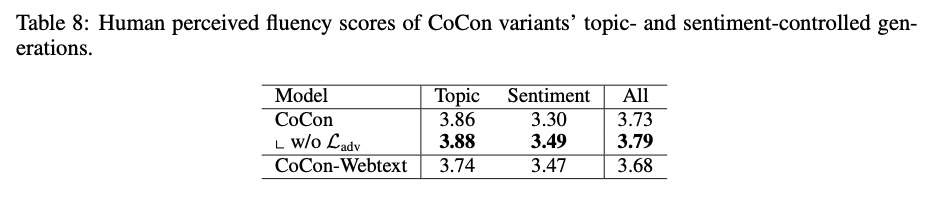
- Human evaluation 결과에서는 \(\mathcal{L}_{adv}\) 를 제거한 경우가 더 높은 성능을 얻었으며 adversarial training loss가 학습을 어렵게 만든다.
- Fluency score는 1-5점 척도
4. 2. Topic Relevance
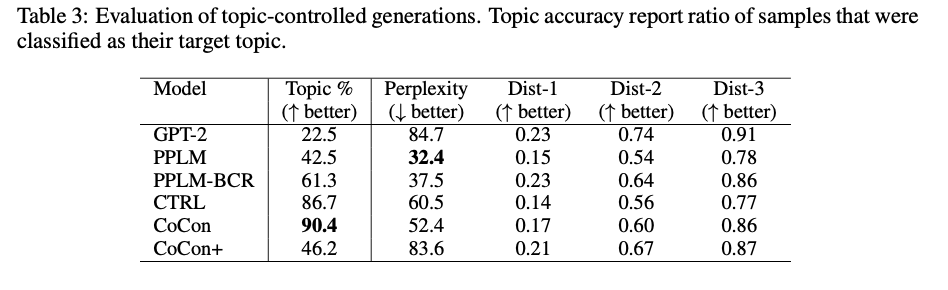
- GPT-2 를 featrue extractor로 사용한 classifier를 만들고 HuffPost News category dataset에 대해 학습 시킨후 생성된 텍스트를 분류하는 방식으로 평가한다.
- PPLM, CTRL, CoCon 모두 GPT-2보다 성능이 높고 CoCon이 성능이 제일 좋다.
- CoCon의 경우 PPLM, CTRL 보다 대체로 diversity도 높음
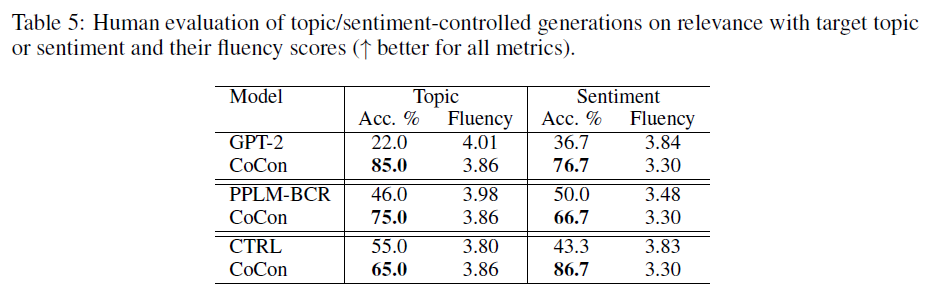
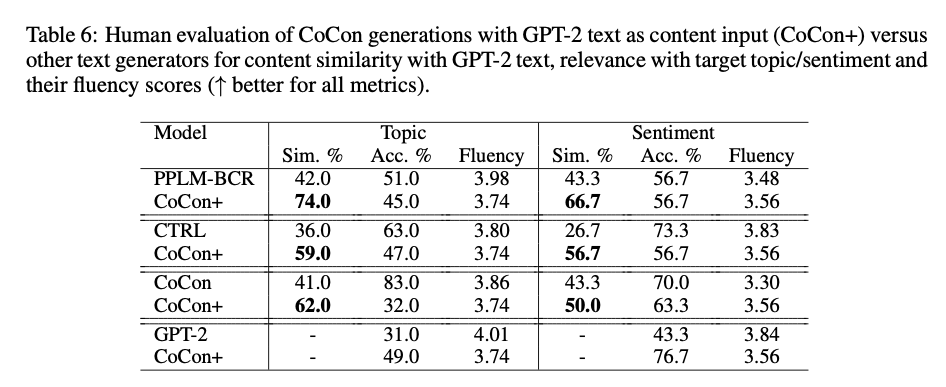
- Human evaluation 에서도 다른 모델들에 비해 control 측면에서 좋은 평가를 얻는다.
- Acc 의 경우 A/B 테스트 (“둘다 나쁨”, “동일” 포함)
- CoCon+에 대해서는 정확히 이해하지 못하였음.
4. 3. Sentiment Control
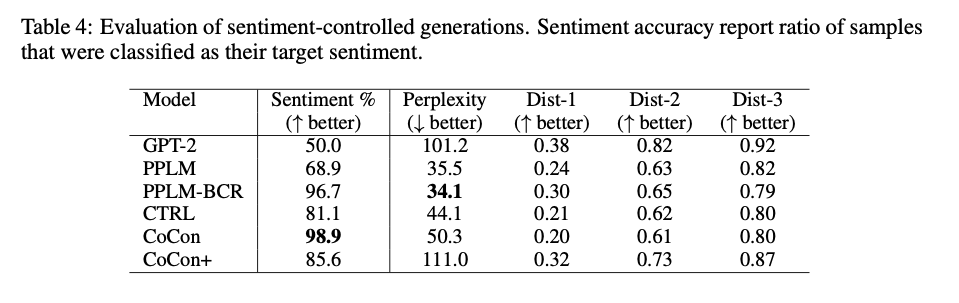
- 위와 마찬가지 방식으로 IDMB Dataset에 대해 학습된 classifier를 이용한다
- Topic relevance와 동일한 경향을 보인다.
4. 4. Versatility of CoCon
- Multiple Content Inputs : 여러개의 content inputs을 사용 가능하다.
- Strength of Content Conditioning : 파라미터를 통해 content conditioning을 조절 가능하다.
- Complementary Text Control : 하나의 모듈로서 PPLM과 같은 다른 LM에 붙여 사용할 수 있다.
Generated examples 은 paper를 참고하자.
5. Conclusion
We proposed Content-Conditioner (CoCon) as an approach for more fine-grained control over neural text generation. CoCon can be trained effectively in a self-supervised manner and is compatible with pretrained language models (LM) that already produce high-quality texts. Through our experiments, CoCon was shown to smoothly incorporate content inputs into generated texts and control high-level text attributes. This new dimension of control over powerful LMs opens them up for even wider range of applications.

Dongju Park
Research Scientist / Engineer @ NAVER CLOVA